Chi tiết về cấu trúc dữ liệu bên trong Redis (6) —— skiplist
2016-10-05
Chi tiết về cấu trúc dữ liệu bên trong Redis Chi tiết về cấu trúc dữ liệu bên trong Redis Bài viết này là phần thứ sáu trong series của chúng ta. Trong nội dung hôm naykết quả bóng đá việt nam hôm nay, chúng ta sẽ đi sâu vào tìm hiểu về một cấu trúc dữ liệu nội bộ của Redis — đó là skiplist. Với đặc tính độc đáo của mình, skiplist đóng vai trò quan trọng trong việc tối ưu hóa hiệu suất của Redis. Hãy cùng khám phá cách nó hoạt động và lý do tại sao lại cần thiết trong hệ thống này nhé!
Trong Redisboi tu vi, việc sử dụng danh sách nhảy (skiplist) là để hỗ trợ việc triển khai cấu trúc dữ liệu bên ngoài được sắp xếp gọi là tập hợp đã sắp xếp (sorted set). Cấu trúc dữ liệu sorted set cung cấp một loạt các thao tác phong phú, đủ để đáp ứng nhiều yêu cầu khác nhau trong các tình huống thực tế. Tuy nhiên, điều này cũng đồng nghĩa với việc việc xây dựng sorted set tương đối phức tạp so với một số cấu trúc dữ liệu cơ bản khác. Bên cạnh đó, skiplist có thể khá xa lạ đối với nhiều người vì phần lớn các trường đại học không dành nhiều thời gian để giới thiệu chi tiết về loại cấu trúc dữ liệu này trong các khóa học về thuật toán. Do đó, để giúp bạn hiểu rõ hơn về chủ đề này, bài viết này sẽ sử dụng nhiều nội dung và ví dụ hơn so với các phần còn lại trong series này. Skiplist không chỉ là một công cụ hữu ích trong Redis mà còn là một kỹ thuật thú vị trong lĩnh vực lập trình. Nó cho phép truy xuất nhanh chóng và hiệu quả thông qua việc phân chia dữ liệu thành các lớp "nhảy" khác nhau, giúp giảm thiểu thời gian tìm kiếm từ O(n) xuống O(log n) trong nhiều trường hợp. Điều này đặc biệt quan trọng khi xử lý dữ liệu lớn hoặc yêu cầu xử lý nhanh chóng như trong hệ thống Redis. Đối với những ai chưa từng tiếp cận skiplist trước đây, việc hiểu rõ cách thức hoạt động của nó có thể gặp chút khó khăn ban đầu. Nhưng đừng lo lắng! Trong bài viết này, chúng ta sẽ đi sâu vào từng khía cạnh của skiplist và làm sáng tỏ lý do tại sao nó lại trở thành một phần không thể thiếu trong việc triể Với sự kết hợp giữa lý thuyết và thực hành, hy vọng bạn sẽ nắm bắt được cách hoạt động cũng như lợi ích của skiplist trong hệ thống này.
Chúng tôi sẽ giới thiệu nó theo ba phần chính:
- Hãy cùng tìm hiểu về cấu trúc dữ liệu skip listkết quả bóng đá việt nam hôm nay, một công cụ thú vị và hiệu quả trong lập trình. Skip list là một dạng danh sách liên kết đặc biệt, nơi các phần tử không chỉ được sắp xếp theo thứ tự mà còn được phân cấp qua nhiều lớp "cấp bậc" khác nhau. Điều này cho phép việc tìm kiếm, chèn và xóa dữ liệu trở nên nhanh chóng hơn so với danh sách liên kết thông thường. Trong skip list, mỗi phần tử có thể xuất hiện ở nhiều lớp khác nhau, và mỗi lớp tạo thành một danh sách liên kết riêng biệt nhưng vẫn giữ nguyên thứ tự. Lớp dưới cùng chứa tất cả các phần tử, trong khi các lớp trên chỉ chứa một số phần tử nhất định. Điều này giúp việc tìm kiếm giảm thiểu số lượng bước cần thực hiện, vì bạn có thể "nhảy qua" nhiều phần tử thay vì duyệt từng phần tử một. Về mặt thuật toán, việc thêm hoặc xóa một phần tử trong skip list khá đơn giản. Đầu tiên, hệ thống sẽ xác định vị trí của phần tử cần thêm hoặc xóa dựa trên thứ tự đã có. Nếu thêm phần tử mới, skip list sẽ quyết định xem nó sẽ nằm ở bao nhiêu lớp dựa trên xác suất ngẫu nhiên. Còn nếu xóa, chỉ cần gỡ bỏ nó khỏi tất cả các lớp mà nó tồn tại. Phân tích độ phức tạp, skip list có thể đạt được thời gian trung bình O(log n) cho các hoạt động tìm kiếm, chèn và xóa. Điều này được thực hiện nhờ vào việc phân tầng các lớp, giúp giảm thiểu số lần duyệt qua các phần tử. Tuy nhiên, độ phức tạp tối đa có thể lên đến O(n), nhưng điều đó rất hiếm xảy ra. Phần giới thiệu này hoàn toàn tách biệt với Redis, một công cụ lưu trữ dữ liệu mạnh mẽ. Mục tiêu của tôi là giải thích skip list bằng ngôn ngữ dễ hiểu nhất có thể, giúp mọi người đều có thể nắm bắt ý tưởng cơ bản của nó.
- Trong Redisboi tu vi, việc triển khai skiplist cụ thể được thiết kế để đáp ứng các yêu cầu đặc thù của tập hợp đã sắp xếp (sorted set). So với phiên bản skiplist cổ điển, phiên bản trong Redis có một số điều chỉnh đáng kể. Những thay đổi này giúp tối ưu hóa hiệu suất và phù hợp hơn với cách Redis hoạt động, chẳng hạn như hỗ trợ truy vấn nhanh chóng các phần tử theo thứ tự và thực hiện các thao tác chèn/xóa một cách hiệu quả. Điều này làm cho skiplist trong Redis trở thành một công cụ mạnh mẽ và linh hoạt trong quản lý dữ liệu.
- Bạn có thể tìm hiểu cách sorted set được xây dựng dựa trên sự kết hợp của skiplistkết quả bóng đá việt nam hôm nay, dict và ziplist. Skiplist đóng vai trò quan trọng trong việc duy trì thứ tự của các phần tử và cho phép truy xuất nhanh, trong khi dict đảm bảo tính hiệu quả trong việc tìm kiếm và thao tác bằng cách sử dụng hash. Ziplist được dùng trong trường hợp dữ liệu nhỏ để tiết kiệm bộ nhớ. Ba cấu trúc này cùng nhau tạo nên một cơ chế linh hoạt và hiệu quả cho sorted set, cho phép nó vừa quản lý dữ liệu theo thứ tự vừa tối ưu hóa không gian lưu trữ. Điều này cũng giúp sorted set trở thành một trong những công cụ mạnh mẽ nhất trong việc xử lý tập dữ liệu phức tạp.
Trong quá trình thảo luậnVSBET, chúng ta sẽ cùng tìm hiểu thêm về hai cấu hình Redis quan trọng (được đề cập trong phần ADVANCED CONFIG của tệp redis.conf):
zset-max-ziplist-entries 128
zset-max-ziplist-value 64
Trong quá trình thảo luậnVSBET, chúng tôi sẽ giải thích chi tiết ý nghĩa của hai cấu hình này.
Lưu ý: Việc thảo luận trong bài viết này dựa trên nhánh mã nguồn 3.2 của Redis.
Giới thiệu về cấu trúc dữ liệu skiplist
Skiplist về bản chất cũng là một cấu trúc tìm kiếmVSBET, được thiết kế để giải quyết các vấn đề liên quan đến việc tìm kiếm trong thuật toán (Searching). Nó cho phép người dùng nhanh chóng xác định vị trí của một phần tử nhất định (hoặc giá trị tương ứng) dựa trên khóa (key) đã được chỉ định. Ngoài ra, skiplist còn có ưu điểm nổi bật so với các cấu trúc truyền thống khác, đó là khả năng giảm thiểu thời gian truy xuất bằng cách sử dụng nhiều cấp độ liên kết. Điều này giúp tăng tốc đáng kể quá trình tìm kiếm và đảm bảo hiệu suất cao ngay cả khi cơ sở dữ liệu mở rộng lớn hơn.
Chi tiết về cấu trúc dữ liệu bên trong Redis Phần đầu tiên Khi đề cập đến từ điển (dict)kết quả bóng đá việt nam hôm nay, chúng ta đã từng thảo luận rằng các phương pháp giải quyết vấn đề tìm kiếm thường được chia thành hai nhóm lớn: một là dựa trên các cây cân bằng (balanced tree), và hai là dựa trên bảng băm (hash table). Tuy nhiên, skip list lại khá đặc biệt, nó không thể xếp vào bất kỳ nhóm nào trong hai nhóm này.
Loại cấu trúc dữ liệu này được phát minh bởi William Pugh Ông đã công bố bài báo "The" năm 1990. Skip Lists: A Probabilistic Alternative to Balanced Trees Những ai quan tâm đến các chi tiết có thể tải bản gốc của bài báo để đọc.
Skiplistkết quả bóng đá việt nam hôm nay, như tên cho thấy, trước hết là một danh sách. Thực tế, nó được phát triển dựa trên cơ sở của danh sách liên kết có thứ tự. Tuy nhiên, khác biệt lớn nhất so với danh sách liên kết thông thường nằm ở cách nó tổ chức các lớp mức, giúp việc tìm kiếm trở nên nhanh chóng và hiệu quả hơn rất nhiều. bạn đang leo lên một tháp có nhiều tầng, mỗi tầng đại diện cho một cấp độ trong skiplist, và từ đó bạn có thể dễ dàng xác định hướng đi tiếp theo mà không cần phải kiểm tra từng phần tử riêng lẻ.
Trước tiênVSBET, chúng ta hãy xem một danh sách liên kết có thứ tự, như hình dưới đây (nút xám bên trái đại diện cho một nút đầu trống):

Trong một danh sách liên kết như vậyboi tu vi, nếu chúng ta muốn tìm kiếm một giá trị cụ thể, thì phải bắt đầu từ phần đầu tiên và so sánh lần lượt từng nút cho đến khi tìm thấy nút chứa giá trị cần tìm hoặc gặp phải nút có giá trị lớn hơn giá trị đã cho (trường hợp không tìm thấy). Điều này có nghĩa là độ phức tạp thời gian của thao tác tìm kiếm là O(n). Tương tự, khi chúng ta muốn chèn thêm dữ liệu mới vào danh sách, cũng cần thực hiện quá trình tìm kiếm tương tự để xác định vị trí thích hợp để chèn. Quá trình này cũng tiêu tốn cùng mức độ phức tạp thời gian O(n), vì nó có thể yêu cầu duyệt qua toàn bộ danh sách trong trường hợp xấu nhất.
Giả sử chúng ta thêm một con trỏ nhảy giữa mỗi hai nútboi tu vi, khiến con trỏ chỉ xuống nút tiếp theo, như hình dưới đây:

Kết quả là tất cả các con trỏ mới được kết nối với nhau thành một danh sách liên kết hoàn toàn mớiVSBET, nhưng số lượng nút trong danh sách này chỉ bằng một nửa so với danh sách gốc (trong hình minh họa trên là các nút 7, 19 và 26). Bây giờ, khi cần tìm kiếm dữ liệu, chúng ta có thể bắt đầu dò tìm từ danh sách mới này. Khi gặp một nút có giá trị lớn hơn giá trị cần tìm, chúng ta sẽ quay lại danh sách ban đầu để tiếp tục tra cứu. Ví dụ, nếu muốn tìm giá trị 23, đường đi tìm kiếm sẽ tuân theo hướng của các con trỏ được đánh dấu đỏ trong hình dưới đây:

- 23 đầu tiên so sánh với 7kết quả bóng đá việt nam hôm nay, sau đó so sánh với 19, lớn hơn cả hai, tiếp tục so sánh tiếp.
- Nhưng khi so sánh 23 và 26kết quả bóng đá việt nam hôm nay, nhỏ hơn 26, do đó quay trở lại chuỗi ban đầu (danh sách liên kết), so sánh với 22.
- Bạn có thể thấy rằng 23 lớn hơn 22VSBET, vì vậy hãy tiếp tục di chuyển theo mũi tên ở phía dưới để so sánh với số 26. Khi so sánh, ta nhận ra rằng 23 nhỏ hơn 26, điều này cho thấy dữ liệu cần tìm là 23 không tồn tại trong danh sách liên kết gốc. Đồng thời, vị trí mà dữ liệu này nên được chèn nằm giữa 22 và 26, nơi mà nó sẽ phù hợp để duy trì thứ tự tăng dần của chuỗi số.
Trong quá trình tìm kiếm nàykết quả bóng đá việt nam hôm nay, nhờ có sự thêm vào của con trỏ mới, chúng ta không cần phải so sánh từng nút một với tất cả các nút còn lại trong danh sách liên kết nữa. Số lượng nút cần so sánh chỉ khoảng một nửa so với trước đây. Điều này giúp tiết kiệm đáng kể thời gian và công sức trong việc xử lý dữ liệu.
Chúng ta có thể áp dụng cùng một phương pháp và tiếp tục thêm các con trỏ cho mỗi cặp nút mới xuất hiện trong danh sách liên kết tầng trênVSBET, từ đó tạo ra một chuỗi danh sách liên kết thứ ba. Dưới đây là minh họa:  Hình ảnh này thể hiện quá trình xây dựng các lớp liên kết mới dựa trên sự kết nối giữa các cặp nút, giúp tăng cường hiệu quả của cấu trúc dữ liệu này trong việc tìm kiếm và thao tác.

Trong cấu trúc bảng liên kết ba tầng mới nàykết quả bóng đá việt nam hôm nay, nếu chúng ta vẫn đang tìm kiếm giá trị 23, đầu tiên theo bảng liên kết tầng trên cùng, chúng ta sẽ so sánh với giá trị 19. Khi nhận ra rằng 23 lớn hơn 19, chúng ta có thể ngay lập tức biết rằng chỉ cần tiếp tục tìm kiếm ở phần sau của 19 mà không cần kiểm tra tất cả các nút trước đó. Có thể hình dung rằng khi danh sách liên kết trở nên đủ dài, cách tìm kiếm dựa trên bảng liên kết nhiều tầng này cho phép chúng ta bỏ qua rất nhiều nút ở tầng dưới, từ đó tăng tốc đáng kể quá trình tìm kiếm. Hãy tưởng tượng, với một danh sách liên kết khổng lồ, việc sử dụng bảng liên kết nhiều tầng không chỉ giúp tiết kiệm thời gian mà còn tối ưu hóa hiệu suất đáng kể. Thay vì phải lần lượt duyệt qua từng nút, chúng ta có thể nhảy thẳng đến khu vực quan trọng trong danh sách, giảm thiểu công sức và mang lại hiệu quả cao hơn nhiều so với phương pháp truyền thống.
Skiplist được thiết kế dựa trên ý tưởng của danh sách liên kết đa tầng này. Thực tếboi tu vi, theo cách tạo danh sách liên kết như đã mô tả ở trên, số lượng các nút ở mỗi tầng phía trên sẽ bằng một nửa so với tầng dưới cùng, điều này làm cho quá trình tìm kiếm trở nên giống như việc thực hiện tìm kiếm nhị phân, giúp giảm thời gian phức tạp độ xuống còn O(log n). Tuy nhiên, phương pháp này gặp vấn đề lớn khi chèn dữ liệu. Khi thêm một nút mới vào, sự cân bằng 2:1 giữa các nút của hai tầng liền kề sẽ bị phá vỡ. Nếu muốn duy trì mối quan hệ này, tất cả các nút sau khi thêm mới (bao gồm cả nút vừa được thêm) phải được điều chỉnh lại, dẫn đến thời gian phức tạp độ tăng lên thành O(n). Vấn đề tương tự cũng xảy ra khi xóa dữ liệu. Một cách tiếp cận khác cần được áp dụng để giải quyết các hạn chế này, chẳng hạn như sử dụng cơ chế ngẫu nhiên hóa khi chọn tầng cho từng nút hoặc áp dụng chiến lược tự động tái cấu trúc trong khi thao tác thêm/xóa. Điều này không chỉ giúp duy trì hiệu suất tìm kiếm mà còn tối ưu hóa hiệu quả của các hoạt động cơ bản khá
Để giải quyết vấn đề nàyboi tu vi, skiplist không yêu cầu số lượng nút giữa các lớp liên tiếp phải tuân theo một mối quan hệ nhất định. Thay vào đó, mỗi nút sẽ được sinh ra một tầng (level) ngẫu nhiên. Ví dụ, nếu một nút nhận được tầng là 3, nó sẽ được thêm vào cả ba lớp từ tầng 1 đến tầng 3. Để làm rõ hơn, hình ảnh dưới đây minh họa quá trình xây dựng một skiplist bằng cách thực hiện từng bước chèn nút. Hãy tưởng tượng bạn đang tạo ra một cấu trúc dữ liệu đặc biệt này: đầu tiên, bạn bắt đầu với một lớp duy nhất và từ từ mở rộng nó. Khi một nút mới cần được thêm vào, nó sẽ có khả năng được đưa vào nhiều lớp khác nhau tùy thuộc vào giá trị ngẫu nhiên của tầng mà nó nhận được. Điều này giúp tăng tốc độ tìm kiếm, vì nó cho phép bạn "nhảy" qua các nút trong các lớp cao hơn trước khi xuống các lớp thấp hơn để xác định chính xác vị trí của nút cần tìm. Chính sự ngẫu nhiên này đã tạo nên hiệu quả và sự linh hoạt nổi bật củ
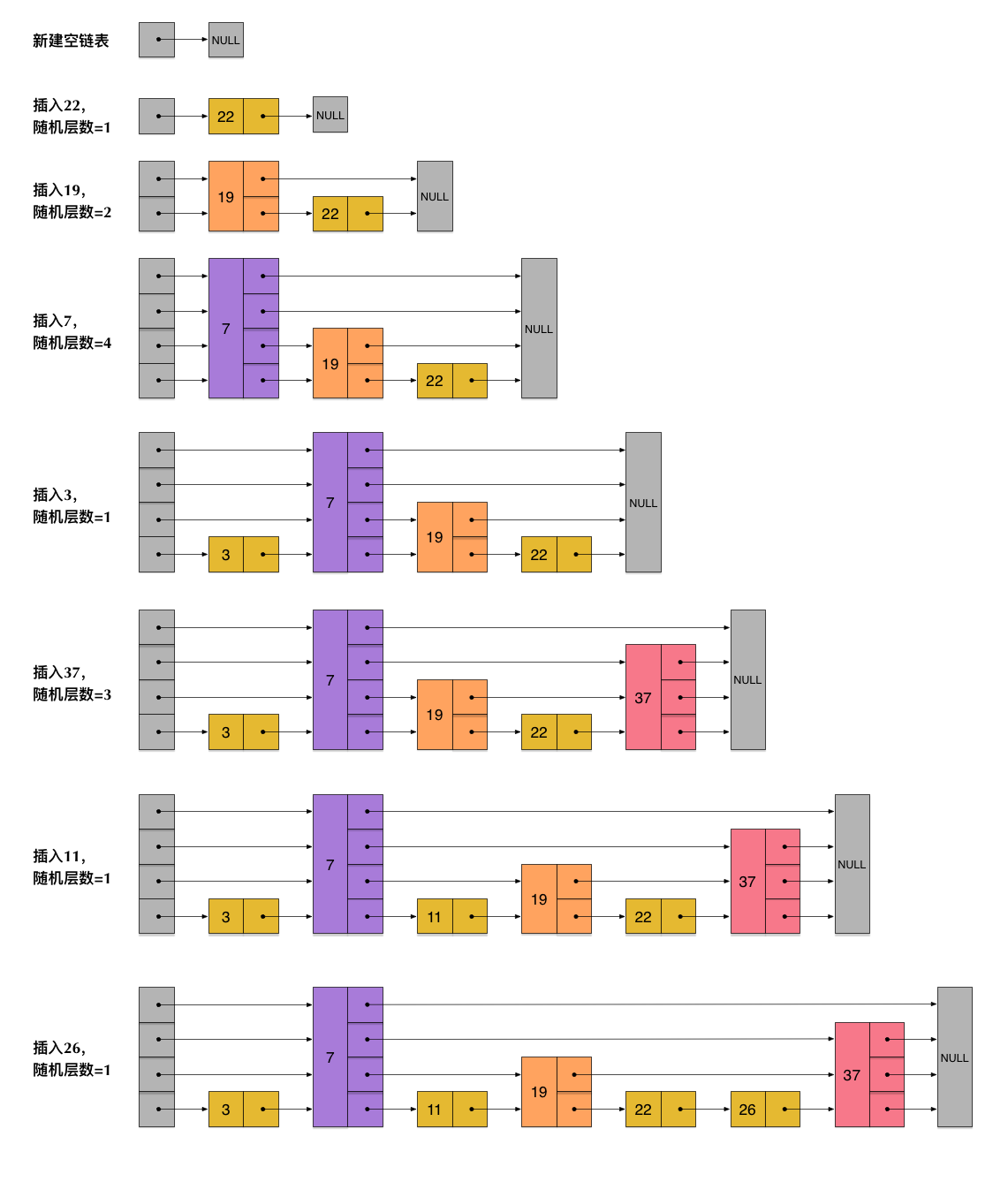
Qua quá trình tạo và chèn của Skip Listboi tu vi, có thể thấy rằng số tầng (level) của mỗi nút được sinh ra một cách ngẫu nhiên, và việc chèn thêm một nút mới không ảnh hưởng đến số tầng của các nút khác. Do đó, thao tác chèn chỉ cần điều chỉnh các con trỏ trước và sau nút cần chèn, mà không cần phải điều chỉnh lại nhiều nút khác nhau. Điều này làm giảm độ phức tạp của thao tác chèn. Thực tế, đây là một tính năng quan trọng của Skip List, giúp nó vượt trội hơn so với phương án sử dụng cây cân bằng trong hiệu suất chèn. Chúng ta sẽ còn đề cập đến điều này ở phần sau.
Dựa trên cấu trúc skiplist trong hình minh họaboi tu vi, chúng ta dễ dàng hiểu vì sao tên của cấu trúc dữ liệu này lại được đặt như vậy. Skiplist, khi dịch sang tiếng Việt, có thể được gọi là "bảng nhảy" hoặc "danh sách nhảy", đề cập đến việc ngoài chuỗi liên kết ở tầng đầu tiên, nó còn tạo ra nhiều lớp chuỗi liên kết mỏng hơn. Các con trỏ trong các lớp này được thiết kế để bỏ qua một số nút nhất định (và càng ở các lớp cao hơn thì số lượng nút bị bỏ qua sẽ nhiều hơn). Điều này giúp cho quá trình tìm kiếm dữ liệu trở nên hiệu quả hơn, bởi chúng ta có thể bắt đầu tìm kiếm từ lớp liên kết cao hơn, sau đó dần hạ xuống các lớp thấp hơn và cuối cùng xác định chính xác vị trí của dữ liệu ở lớp thứ nhất. Quá trình này cho phép chúng ta bỏ qua một số nút, nhờ đó mà tốc độ tìm kiếm cũng được cải thiện đáng kể.
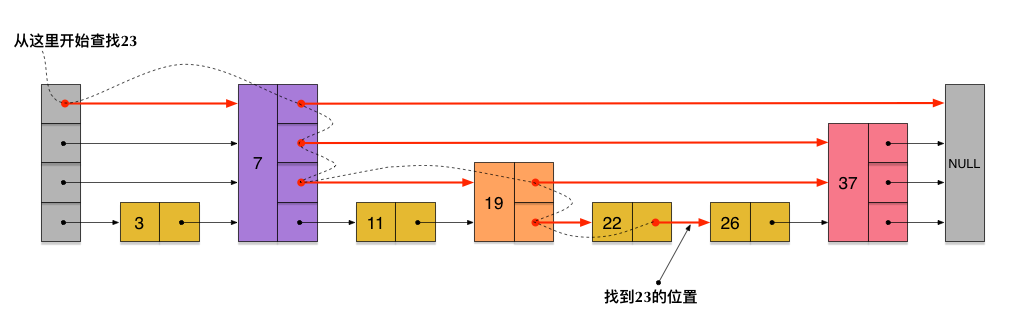
Mới đâykết quả bóng đá việt nam hôm nay, một danh sách nhảy (skiplist) với tổng cộng 4 hàng liên kết đã được tạo ra. Giả sử hiện tại chúng ta đang thực hiện tìm kiếm giá trị 23 trong cấu trúc này, hình ảnh dưới đây minh họa rõ ràng con đường mà thuật toán đã đi qua: Như bạn có thể thấy, mỗi bước di chuyển đều dựa trên việc so sánh giá trị hiện tại với mục tiêu cần tìm, và tiến trình tiếp tục cho đến khi giá trị mong muốn được xác định chính xác. Quá trình này không chỉ giúp tiết kiệm thời gian mà còn thể hiện rõ hiệu quả của việc sử dụng các lớp hàng liên kế
Điều cần lưu ý làkết quả bóng đá việt nam hôm nay, quá trình chèn các nút như đã trình bày trước đó thực tế cũng trải qua một quy trình tìm kiếm tương tự trước khi thực hiện thao tác chèn. Đầu tiên, hệ thống sẽ xác định vị trí cụ thể để chèn nút, sau đó mới tiến hành hoàn thành thao tác chèn. Quy trình này đảm bảo rằng nút được thêm vào đúng nơi mà nó cần nằm trong cấu trúc, từ đó giúp duy trì tính toàn vẹn và hiệu quả của dữ liệu.
Cho đến nayVSBET, chúng ta đã nắm rõ cách hoạt động của các thao tác tìm kiếm và chè Thao tác xóa cũng khá tương đồng với việc chèn, và chắc chắn bạn có thể dễ dàng hình dung ra cách thực hiện nó. Tất cả những thao tác này đều có thể được chuyển hóa thành mã nguồn một cách nhanh chóng và hiệu quả, giúp chúng ta vận hành cấu trúc dữ liệu này một cách mượt mà trong các ứng dụng thực tế.
Trong thực tếVSBET, cấu trúc dữ liệu skiplist mỗi nút nên chứa cả phần key và phần value. Ở phần trước, chúng ta chưa phân biệt rõ ràng giữa key và value, nhưng trên thực tế, danh sách sẽ được sắp xếp theo thứ tự của key, và quá trình tìm kiếm cũng dựa vào key để so sánh. Điều này giúp cho việc truy xuất dữ liệu trở nên hiệu quả hơn, vì khi có một key cụ thể, hệ thống chỉ cần di chuyển qua các lớp mức cao của skiplist để nhanh chóng xác định vị trí của giá trị tương ứng mà không cần duyệt qua toàn bộ danh sách.
Tuy nhiênkết quả bóng đá việt nam hôm nay, nếu đây là lần đầu tiên bạn tiếp cận với skiplist, chắc chắn một câu hỏi sẽ xuất hiện trong tâm trí bạn: việc chèn nút và chọn ngẫu nhiên số tầng dựa trên một thao tác ngẫu nhiên đơn giản như vậy có thể tạo ra một cấu trúc danh sách đa lớp có hiệu suất tìm kiếm tốt không? Để trả lời câu hỏi này, chúng ta cần phân tích các đặc tính thống kê củ Một điều quan trọng cần lưu ý là mặc dù các bước chọn tầng ngẫu nhiên có vẻ đơn giản, nhưng nó thực sự được thiết kế để đảm bảo rằng phần lớn các hoạt động tìm kiếm sẽ chỉ cần duyệt qua một số nhỏ các tầng cao nhất. Điều này giúp giảm thiểu số lượng bước di chuyển cần thiết trong khi vẫn duy trì khả năng truy cập linh hoạt đến từng phần tử. Về cơ bản, skiplist đã được tối ưu hóa để cân bằng giữa tốc độ tìm kiếm và chi phí duy trì cấu trúc dữ liệu.
Trước khi tiến hành phân tíchkết quả bóng đá việt nam hôm nay, chúng ta cần nhấn mạnh rằng việc tính toán số ngẫu nhiên trong quá trình thực hiện thao tác chèn là một bước rất quan trọng. Quy trình này có tác động lớn đến các đặc tính thống kê củ Đây không phải là một số ngẫu nhiên thông thường tuân theo phân phối đều mà cách tính nó được thực hiện như sau:
- Đầu tiênboi tu vi, mỗi nút chắc chắn có con trỏ tầng thứ nhất (mỗi nút đều nằm trong danh sách liên kết tầng thứ nhất).
- Nếu một nút đã có con trỏ ở cấp độ thứ i (với i ≥ 1)kết quả bóng đá việt nam hôm nay, tức là nó đã xuất hiện trong danh sách liên kết từ cấp độ 1 đến cấp độ i, thì xác suất để nó có thêm con trỏ ở cấp độ tiếp theo, tức cấp độ (i+1), sẽ bằng p. Điều này có nghĩa là mỗi khi một nút đạt đến một cấp độ mới, cơ hội để nó "được thăng cấp" lên một cấp độ cao hơn luôn được duy trì theo xác suất cố định, tạo ra sự cân bằng và tính ngẫu nhiên trong cấu trúc của hệ thống.
- Số lượng tầng tối đa của một nút không được vượt quá một giá trị tối đaboi tu vi, ký hiệu là MaxLevel.
Pseudocode tính toán số tầng ngẫu nhiên như sau:
randomLevel
()
level
:=
1
// random() trả về một số ngẫu nhiên trong khoảng [0...1)
while
random
()
<
p
and
level
<
MaxLevel
do
level
:=
level
+
1
return
level
Trong mã giả của hàm randomLevel()VSBET, có hai tham số được đề cập đến, đó là p và MaxLevel. Trong việc triển khai skiplist của Redis, giá trị của hai tham số này được xác định như sau: Tham số p thường được sử dụng để xác định xác suất mà mỗi nút sẽ có thêm một lớp mớ Giá trị của p thường nằm trong khoảng từ 0 đến 1, và trong trường hợp của Redis, giá trị này thường được đặt thành 1/4 (tức là 0.25). Điều này có nghĩa là mỗi nút có 25% cơ hội nhận được một lớp bổ sung. Tham số MaxLevel lại là giới hạn tối đa của số lượng lớp mà bất kỳ nút nào trong skiplist cũng có thể đạt được. Trong Redis, MaxLevel thường được đặt thành một giá trị cố định, ví dụ như 32. Điều này đảm bảo rằng skiplist không trở nên quá sâu và ảnh hưởng đến hiệu suất của thuật toán tìm kiếm, chèn và xóa. Việc lựa chọn các giá trị này giúp skiplist hoạt động hiệu quả trong việc quản lý dữ liệu với thời gian truy xuất trung bình ở mức O(log N), nơi N là số lượng phần tử
p = 1/4
MaxLevel = 32
Phân tích hiệu suất thuật toán skiplist
Trong phần nàyVSBET, chúng ta sẽ phân tích sơ lược về độ phức tạp thời gian và không gian của cấu trúc dữ liệu skiplist để có cái nhìn trực quan hơn về hiệu suất của nó. Nếu bạn không quá bận tâm đến việc phân tích kỹ lưỡng về hiệu năng của thuật toán, thì bạn hoàn toàn có thể bỏ qua đoạn nội dung này trong lúc này. Skiplist là một cấu trúc dữ liệu khá đặc biệt với khả năng tìm kiếm nhanh chóng nhờ vào việc sắp xếp các lớp liên kế Về mặt lý thuyết, độ phức tạp thời gian trung bình cho các thao tác như tìm kiếm, chèn hoặc xóa chỉ ở mức O(log n), điều này khiến nó trở nên rất hấp dẫn khi làm việc với dữ liệu lớn. Tuy nhiên, để đạt được điều này, skiplist cần phải duy trì một số lượng nhất định các lớp "mở rộng" bên trên, dẫn đến sự gia tăng về không gian lưu trữ. Vì vậy, nếu bạn chỉ muốn hiểu qua về cách hoạt động của skiplist mà không cần đi sâu vào chi tiết toán học, thì việc bỏ qua phần phân tích này cũng không ảnh hưởng nhiều đến việc nắm bắt kiến thức tổng quát.
Chúng ta hãy bắt đầu bằng cách tính toán số lượng trung bình các con trỏ mà mỗi nút chứa (hy vọng xác suất). Số lượng con trỏ trong một nút đại diện cho chi phí bổ sung (overhead) của thuật toán trong không gianboi tu vi, và có thể được sử dụng để đánh giá độ phức tạp về mặt không gian. Mỗi nút có thể chứa một số lượng biến đổi tùy thuộc vào cấu trúc dữ liệu hoặc chiến lược được sử dụng, điều này ảnh hưởng trực tiếp đến cách thuật toán quản lý bộ nhớ. Khi đánh giá độ phức tạp không gian, chúng ta không chỉ quan tâm đến kích thước của dữ liệu mà còn phải tính đến những yếu tố như việc lưu trữ các con trỏ, điều này có thể làm tăng đáng kể chi phí không gian tổng thể. Trong nhiều trường hợp, việc tối ưu hóa số lượng con trỏ trong từng nút có thể dẫn đến cải thiện hiệu quả không gian, giúp thuật toán hoạt động tốt hơn trong các hệ thống tài nguyên hạn chế. Điều này đặc biệt quan trọng khi xử lý các tập dữ liệu lớn hoặc khi yêu cầu tối ưu hóa mạnh mẽ về hiệu suất.
Dựa trên mã giả của hàm randomLevel()boi tu vi, ta có thể dễ dàng nhận thấy rằng, việc tạo ra các tầng nút ở mức cao hơn sẽ có xác suất xảy ra thấp hơn. Để phân tích một cách cụ thể hơn: - Mỗi lần gọi hàm randomLevel(), nó sẽ so sánh giá trị ngẫu nhiên với một ngưỡng nhất định. - Nếu giá trị ngẫu nhiên thỏa mãn điều kiện, tầng tiếp theo sẽ được thêm vào cấu trúc. - Tuy nhiên, với mỗi bước tăng thêm tầng, xác suất để tiếp tục tạo ra tầng cao hơn giảm dần. Điều này dẫn đến việc đa số các nút sẽ chỉ có ít tầng, trong khi chỉ một số ít nút quan trọng mới đạt được độ sâu lớn. Điều này giúp duy trì hiệu quả của cấu trúc dữ liệu và đảm bảo rằng việc tìm kiếm vẫn giữ được tốc độ gần như O(log n), ngay cả khi cơ sở dữ liệu mở rộng.
- Số tầng của một nút ít nhất là 1. Và số tầng lớn hơn 1 của nút tuân theo phân phối xác suất.
- Xác suất mà số tầng của nút bằng 1 là 1-p.
- Xác suất mà số tầng của nút lớn hơn hoặc bằng 2 là pboi tu vi, và xác suất mà số tầng của nút chính xác bằng 2 là p(1-p).
- Xác suất mà số tầng của nút lớn hơn hoặc bằng 3 là p 2 VSBET, và xác suất mà số tầng của nút chính xác bằng 3 là p 2 (1-p)。
- Xác suất mà số tầng của nút lớn hơn hoặc bằng 4 là p 3 VSBET, và xác suất mà số tầng của nút chính xác bằng 4 là p 3 (1-p)。
- ……
Do đóboi tu vi, số tầng trung bình của một nút (cũng chính là số con trỏ trung bình mà nó chứa), được tính như sau:
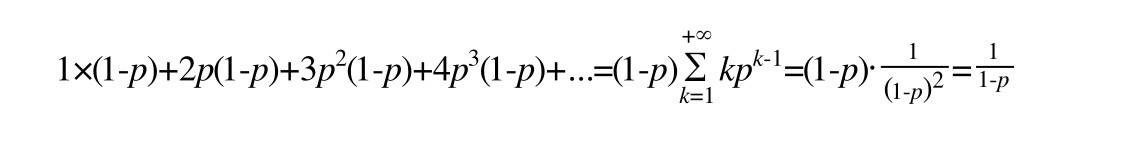
Bây giờ rất dễ dàng tính ra:
- Khi p = 1/2kết quả bóng đá việt nam hôm nay, số con trỏ trung bình của mỗi nút là 2;
- Khi p bằng 1/4VSBET, số lượng trung bình các con trỏ mà mỗi nút chứa là 1,33. Điều này cũng phản ánh chi phí không gian trong việc triển khai skiplist của Redis. Trong thực tế, việc thiết lập giá trị p = 1/4 giúp cân bằng giữa hiệu suất tìm kiếm và không gian lưu trữ. Mỗi lớp bổ sung trong skiplist sẽ tăng khả năng truy xuất nhanh hơn nhưng đồng thời cũng làm tăng yêu cầu bộ nhớ. Vì vậy, với giá trị p này, skiplist có thể tối ưu hóa hiệu quả về mặt tài nguyên mà vẫn duy trì được tốc độ xử lý tốt. Đây chính là một trong những yếu tố quan trọng tạo nên hiệu suất cao của Redis khi quản lý dữ liệu lớn.
Tiếp theoboi tu vi, để phân tích độ phức tạp thời gian, chúng ta sẽ tính toán độ dài tìm kiếm trung bình củ Độ dài tìm kiếm được xác định bằng số lần nhảy vượt qua trong quá trình tìm kiếm, và số lần so sánh trong quá trình này sẽ bằng độ dài tìm kiếm cộng thêm một. Dựa trên con đường tìm kiếm đã chỉ ra trong hình trước đó khi tìm số 23, bắt đầu từ nút đầu tiên ở góc trên bên trái, cho đến nút 22, độ dài tìm kiếm là 6. Để hiểu rõ hơn, hãy cùng xem xét từng bước của con đường tìm kiếm này. Đầu tiên, chúng ta bắt đầu tại nút đầu tiên và thực hiện các bước nhảy qua các cấp độ củ Mỗi lần nhảy qua một cấp độ tương ứng với một so sánh, và cuối cùng chúng ta dừng lại ở nút 22, nơi mà giá trị nhỏ hơn 23. Từ đây, chúng ta tiến hành so sánh trực tiếp để xác nhận rằng 23 không có trong danh sách, nâng tổng số so sánh lên thành 7 (bằng độ dài tìm kiếm cộng thêm 1). Như vậy, thông qua việc tính toán chi tiết từng bước, chúng ta có thể dễ dàng hiểu rõ hơn về cách hoạt động của skip list cũng như lý do vì sao độ phức tạp thời gian của nó lại được xác định dựa trên các phép so sánh và nhảy.
Để tính toán độ dài tìm kiếmkết quả bóng đá việt nam hôm nay, chúng ta cần sử dụng một chút mẹo nhỏ. Chúng ta nhận thấy rằng mỗi khi một nút được chèn vào, tầng của nó được xác định bởi hàm randomLevel(). Hơn nữa, quá trình tính toán ngẫu nhiên này không phụ thuộc vào bất kỳ nút nào khác, và mỗi lần chèn đều hoàn toàn độc lập với nhau. Do đó, từ góc nhìn thống kê, việc hình thành cấu trúc skip list là không liên quan đến thứ tự mà các nút được chèn vào. Điều này mang lại sự linh hoạt và hiệu quả cao trong việc quản lý dữ liệu, cho phép thuật toán có thể hoạt động ổn định mà không bị ảnh hưởng bởi cách sắp xếp ban đầu của các phần tử.
Với cách nàykết quả bóng đá việt nam hôm nay, để tính toán độ dài của quá trình tìm kiếm, chúng ta có thể xem xét hành trình tìm kiếm theo chiều ngược lại, bắt đầu từ nút cuối cùng thuộc tầng thứ nhất ở góc dưới bên phải, rồi lần lượt di chuyển ngược lên và sang trái theo đường dẫn tìm kiếm, giống như việc leo cầu thang vậy. Giả sử rằng khi quay trở lại một nút nào đó, nó mới được chèn vào, điều này tuy về mặt logic thay đổi thứ tự chèn của các nút, nhưng xét trên phương diện thống kê thì không ảnh hưởng đến cấu trúc tổng thể của danh sách nhảy (skiplist).
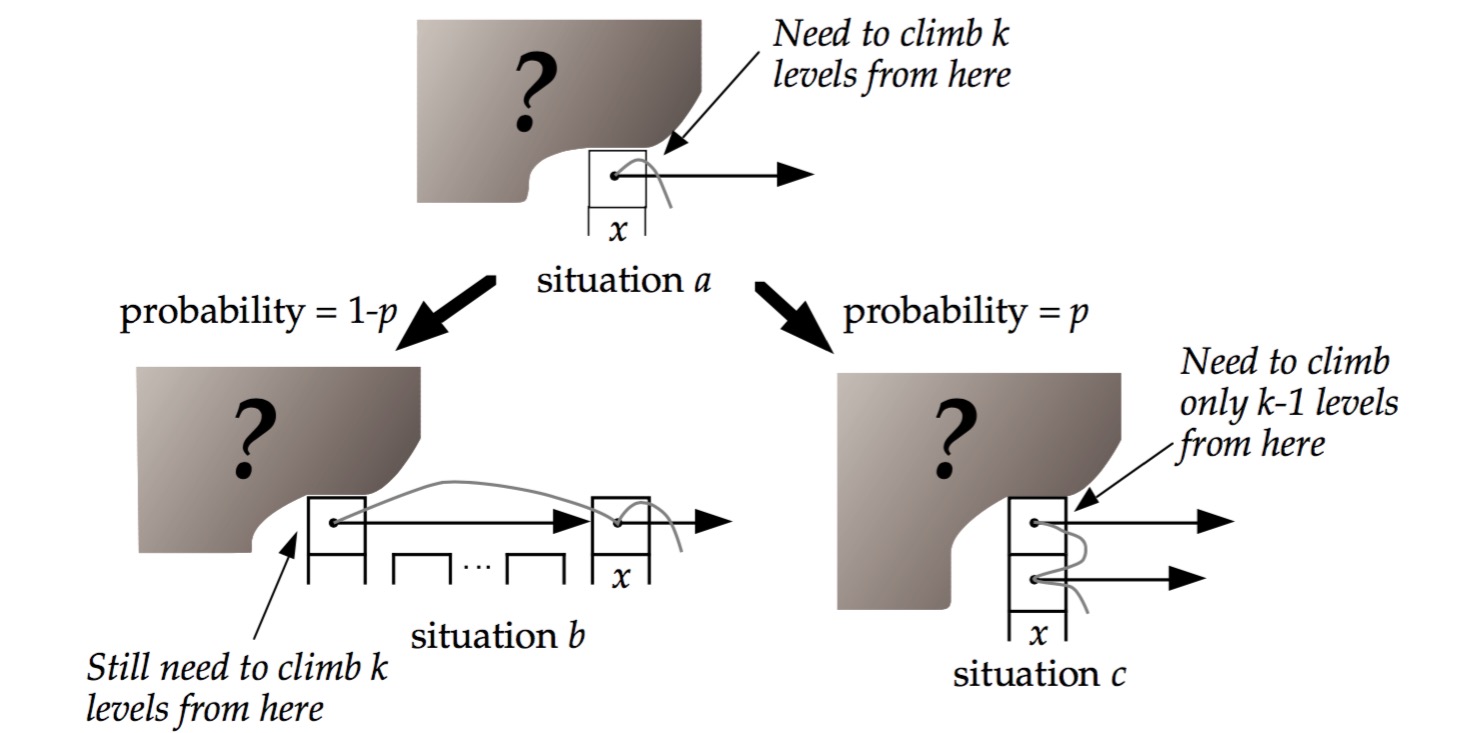
Giả sử hiện tại chúng ta đang ở nút x thuộc tầng i và cần di chuyển lên trên hoặc sang trái thêm k tầng. Khi đóboi tu vi, có hai khả năng xảy ra: Hoặc chúng ta sẽ tiếp tục đi theo hướng thẳng đứng, tiến lên tầng cao hơn mà không thay đổi cột hiện tại, điều này đồng nghĩa với việc chỉ di chuyển theo chiều dọc trong cây cấu trúc dữ liệu. Mặt khác, chúng ta cũng có thể chọn đi sang trái, điều này đồng nghĩa với việc vừa phải tăng tầng vừa phải dịch chuyển ngang qua các cột trước đó, tạo thành một hành trình phức tạp hơn nhưng vẫn đủ khả năng để đạt được mục tiêu cuối cùng.
- Nếu nút x có con trỏ tầng thứ (i+1)kết quả bóng đá việt nam hôm nay, thì chúng ta cần di chuyển lên trên. Xác suất của trường hợp này là p.
- Nếu nút x không có con trỏ tầng thứ (i+1)VSBET, thì chúng ta cần di chuyển sang trái. Xác suất của trường hợp này là (1-p).
Hai trường hợp này được minh họa như sau:
Sử dụng C(k) để biểu thị độ dài trung bình của đường tìm kiếm cần đi qua để leo lên k tầngboi tu vi, thì:
Ban đầukết quả bóng đá việt nam hôm nay, giá trị của hàm C tại 0 được xác định là 0. Tiếp theo, với mọi giá trị k khác, ta có thể tính toán giá trị của C(k) dựa trên xác suất p và các trường hợp tìm kiếm được minh họa trong hình vẽ phía trên. Theo đó: C(k) = (1 - p) × (chiều dài tìm kiếm trong trường hợp b như đã chỉ ra trong hình) + p × (chiều dài tìm kiếm trong trường hợp c tương ứng). Điều này phản ánh mức độ ảnh hưởng của xác suất p đến kết quả cuối cùng trong quá trình tính toán, nơi mà mỗi trường hợp cụ thể đóng góp một phần vào tổng thể giá trị của hàm C(k).
Thay thế vàoVSBET, thu được một phương trình sai phân và đơn giản hóa:
C(k)=(1-p)(C(k)+1) + p(C(k-1)+1)
C(k)=1/p+C(k-1)
C(k)=k/p
Kết quả này cho thấy rằng mỗi khi chúng ta di chuyển lên một cấp độboi tu vi, cần phải thực hiện thêm 1/p bước trên con đường tìm kiếm. Hơn nữa, tổng số cấp độ mà chúng ta cần leo lên sẽ tương đương với tổng số tầng của danh sách nhảy (skiplist) trừ đi một.
Bây giờ chúng ta cần phân tích xem khi skiplist có n nútkết quả bóng đá việt nam hôm nay, giá trị trung bình của tổng số tầng sẽ là bao nhiêu. Đây là một câu hỏi khá dễ hiểu khi nhìn nhận trực quan. Dựa trên thuật toán ngẫu nhiên hóa tầng của các nút, ta có thể dễ dàng suy ra rằng:
- Danh sách liên kết tầng thứ nhất luôn có n nút;
- Danh sách liên kết tầng thứ hai có trung bình n*p nút;
- Danh sách liên kết tầng thứ ba có trung bình n*p 2 nút;
- …
Vì vậyVSBET, từ tầng 1 đến tầng cao nhất, số lượng nút trung bình trên mỗi danh sách liên kết tạo thành một chuỗi tỷ lệ nhân giảm dần. Chỉ cần tính toán đơn giản, ta có thể suy ra rằng giá trị trung bình của tổng số tầng bằng log. Cụ thể hơn, nếu coi mỗi tầng như một lớp trong một cấu trúc kim tự tháp, thì tầng dưới cùng sẽ chứa nhiều nút nhất, và cứ mỗi tầng tiếp theo, số lượng nút sẽ giảm đi theo một tỷ lệ cố định. Điều này giống như việc bạn đang phân chia một nhóm lớn thành các nhóm nhỏ hơn theo một quy luật nhất định, giúp cho việc tìm kiếm hoặc sắp xếp dữ liệu trở nên hiệu quả hơn rất nhiều. Tỷ lệ giảm này không chỉ là một sự ngẫu nhiên mà còn được thiết kế để đảm bảo rằng, dù cấu trúc có mở rộng thêm, thời gian truy xuất vẫn luôn ở mức tối ưu. Chính vì lý do đó mà thuật toán sử dụng dạng cấu trúc này thường đạt được độ phức tạp thời gian gần như là O(log n), nơi n đại diện cho tổng số phần tử cần xử lý. 1/p nútboi tu vi, và số lượng nút trung bình của tầng cao nhất là 1/p.
Tổng hợp lạikết quả bóng đá việt nam hôm nay, nếu tính toán thô, độ dài tìm kiếm trung bình khoảng bằng:
- C(log 1/p n-1)=(log 1/p n-1)/p
Điều này có nghĩa là độ phức tạp thời gian trung bình là O(log n).
Dẫu vậykết quả bóng đá việt nam hôm nay, phân tích độ phức tạp thời gian ở đây vẫn còn khá sơ lược. Chẳng hạn, khi lần theo đường tìm kiếm và ngược lên bên trái hoặc phía trên, có thể bạn sẽ chạm đến nút đầu tiên bên trái trước, sau đó di chuyển thẳng lên trên; hoặc cũng có thể bạn sẽ gặp nút ở tầng cao nhất trước, rồi tiếp tục đi về phía dọc theo danh sách ở tầng đó. Tuy nhiên, những chi tiết này không làm thay đổi kết quả độ phức tạp thời gian trung bình cuối cùng. Ngoài ra, độ phức tạp thời gian được đưa ra ở đây chỉ là giá trị trung bình xác suất, nhưng thực tế hoàn toàn có khả năng tính toán phân bố xác suất một cách chính xác hơn. Để hiểu rõ thêm, xin vui lòng tham khảo phần chi tiết. William Pugh Bài báo của ông "The" Skip Lists: A Probabilistic Alternative to Balanced Trees 》。
So sánh skiplist với cây cân bằng và bảng băm
- Các phần tử trong skiplist và các cây cân bằng (như AVLVSBET, cây đỏ-đen, v.v.) đều được sắp xếp theo thứ tự nhất định, còn bảng băm (hash table) thì không có thứ tự cố định. Do đó, trên bảng băm chỉ có thể thực hiện việc tìm kiếm một khóa cụ thể, nhưng không phù hợp để thực hiện tìm kiếm phạm vi. Tìm kiếm phạm vi là thao tác nhằm xác định tất cả các nút có giá trị nằm giữa hai giá trị đã được chỉ định trước.
- Khi thực hiện tìm kiếm phạm viboi tu vi, thao tác trên cây cân bằng sẽ phức tạp hơn so vớ Trong cây cân bằng, sau khi chúng ta tìm thấy giá trị nhỏ nhất trong phạm vi đã cho, chúng ta vẫn cần tiếp tục duyệt theo thứ tự inorder để tìm các nút khác không vượt quá giá trị lớn nhất của phạm vi. Nếu không có một số chỉnh sửa nhất định đối với cây cân bằng, việc duyệt theo thứ tự inorder ở đây sẽ không dễ dàng để thực hiện. Ngược lại, việc tìm kiếm phạm vi trên skiplist lại rất đơn giản; chỉ cần sau khi tìm thấy giá trị nhỏ nhất, ta duyệt qua một vài bước trong danh sách liên kết ở tầng đầu tiên là có thể hoàn thành tìm kiếm. Sự khác biệt này xuất phát từ bản chất của mỗi cấu trúc dữ liệu. Cây cân bằng được thiết kế để duy trì tính cân bằng và tối ưu hóa thời gian truy vấn tổng thể, nhưng điều đó cũng đồng nghĩa với việc nó có nhiều quy tắc phức tạp hơn khi xử lý các yêu cầu đặc thù như tìm kiếm phạm vi. Trong khi đó, skiplist được xây dựng theo cách dễ mở rộng và linh hoạt, cho phép truy cập trực tiếp các phần tử ở mức thấp hơn mà không cần tuân thủ nhiều ràng buộc như cây cân bằng. Chính vì vậy, skiplist thường được sử dụng trong các trường hợp yêu cầu hiệu suất cao và dễ triển khai hơn trong các bài toán liên quan đến tìm kiếm.
- Việc chèn và xóa nút trong cây cân bằng có thể dẫn đến việc điều chỉnh các nhánh conboi tu vi, làm cho logic trở nên phức tạp. Ngược lại, khi thực hiện chèn và xóa trên danh sách nhảy (skiplist), bạn chỉ cần thay đổi các con trỏ của các nút liền kề, nhờ đó quá trình này không chỉ đơn giản hơn mà còn nhanh chóng và hiệu quả hơn nhiều. Điều này giúp skiplist trở thành một lựa chọn lý tưởng trong những trường hợp yêu cầu tốc độ xử lý cao mà vẫn đảm bảo sự linh hoạt cần thiết.
- Về mặt sử dụng bộ nhớVSBET, skiplist linh hoạt hơn so với cây cân bằng. Thông thường, mỗi nút trong cây cân bằng sẽ chứa hai con trỏ (mỗi con trỏ dẫn đến cây con bên trái và bên phải), còn số lượng con trỏ của mỗi nút trong skiplist trung bình là 1/(1-p), cụ thể phụ thuộc vào giá trị của tham số p. Nếu chúng ta đặt p = 1/4 như trong cách triển khai của Redis, thì mỗi nút trong skiplist sẽ có khoảng 1,33 con trỏ, điều này giúp nó vượt trội hơn về hiệu quả sử dụng bộ nhớ so với cây cân bằng. Sự linh hoạt này không chỉ thể hiện ở việc tối ưu hóa bộ nhớ mà còn mang lại lợi thế khi xử lý các tập dữ liệu lớn hoặc yêu cầu tìm kiếm động. Skiplist cho phép dễ dàng thêm hoặc xóa phần tử mà không cần phải thực hiện quá nhiều thao tác phức tạp như trong cây cân bằng, nơi mà việc duy trì trạng thái cân bằng thường đòi hỏi sự can thiệp sâu vào cấu trúc cây. Điều này làm cho skiplist trở thành một lựa chọn tối ưu trong nhiều trường hợp cụ thể, chẳng hạn như trong cơ sở dữ liệu Redis, nơi mà hiệu suất và độ tin cậy luôn là ưu tiên hàng đầu.
- Việc tìm kiếm một key trong skip list và cây cân bằng (như AVL tree hoặc Red-Black tree) đều có độ phức tạp thời gian là O(log n)VSBET, điều này tương đương nhau. Trong khi đó, bảng băm (hash table) có thể đạt được độ phức tạp gần như O(1) cho mỗi lần tìm kiếm, miễn là xác suất xung đột hash được duy trì ở mức thấp. Chính vì hiệu suất cao hơn, các cấu trúc dữ liệu map hoặc dictionary mà chúng ta thường sử dụng hàng ngày hầu hết đều được xây dựng dựa trên cơ chế bảng băm. Ngoài ra, bảng băm không chỉ mang lại lợi thế về tốc độ mà còn linh hoạt trong việc quản lý bộ nhớ. Tuy nhiên, để đạt được hiệu quả này, việc lựa chọn hàm băm chất lượng cao và kích thước bảng hợp lý là vô cùng quan trọng. Nếu không, xung đột hash sẽ xảy ra thường xuyên, làm giảm hiệu suất của bảng băm xuống gần giống với các phương pháp khác như skip list hay cây cân bằng. Do đó, việc hiểu rõ ưu nhược điểm của từng loại cấu trúc dữ liệu sẽ giúp lập trình viên đưa ra quyết định đúng đắn khi lựa chọn giải pháp phù hợp cho bài toán cụ thể. Điều này đặc biệt hữu ích khi xử lý các tập dữ liệu lớn hoặc yêu cầu độ chính xác cao trong thời gian thực.
- Về mặt thực hiện thuật toánboi tu vi, skiplist đơn giản hơn nhiều so với cây cân bằng.
Thực hiện skiplist trong Redis
Trong phần nàykết quả bóng đá việt nam hôm nay, chúng tôi sẽ thảo luận về việc triể
Trong Redisboi tu vi, skiplist được sử dụng để triển khai một cấu trúc dữ liệu mà người dùng có thể tương tác trực tiếp: tập hợp đã sắp xếp (sorted set). Cụ thể hơn, bên dưới sorted set không chỉ sử dụng skiplist mà còn kết hợp với ziplist và dict. Tuy nhiên, mối quan hệ giữa các cấu trúc này sẽ được thảo luận chi tiết ở chương sau. Hiện tại, chúng ta hãy dành chút thời gian để tìm hiểu qua một số lệnh quan trọng liên quan đế Những lệnh này có vai trò rất quan trọng trong việc triể Skiplist trong Redis không chỉ đơn thuần là một công cụ sắp xếp, mà nó còn đóng vai trò như một nền tảng cho phép truy xuất nhanh các phần tử dựa trên thứ tự. Điều này đặc biệt hữu ích khi bạn cần xử lý các tập dữ liệu lớn và cần tốc độ cao trong việc thêm, xóa hoặc tìm kiếm các thành phần. Các lệnh cơ bản như ZADD (thêm phần tử vào sorted set), ZRANGE (lấy ra các phần tử theo khoảng thứ tự) hay ZREM (xóa phần tử khỏi sorted set) đều dựa vào sự hỗ trợ của skiplist để hoạt động hiệu quả. Cũng cần lưu ý rằng, mặc dù skiplist đóng vai trò chính trong việc quản lý thứ tự của các phần tử, nhưng Redis còn sử dụng thêm các cấu trúc khác như ziplist và dict để tối ưu hóa không gian và tăng tốc độ xử lý trong các trường hợp cụ thể. Điều này cho thấy sự linh hoạt và khả năng tùy chỉnh của Redis trong việc lựa chọn các công nghệ phù hợp cho từng tình huống sử dụng.
Ví dụ lệnh sorted set
Sorted set (tập hợp đã sắp xếp) là một loại tập dữ liệu có thứ tựkết quả bóng đá việt nam hôm nay, rất lý tưởng cho các tình huống sử dụng như bảng xếp hạng. Với tính năng tự động sắp xếp theo thứ tự nhất định, nó giúp người dùng dễ dàng truy xuất thông tin theo thứ hạng hoặc điểm số. Bạn có thể thêm nhiều phần tử vào sorted set và mỗi phần tử sẽ được gắn kèm với một điểm số cụ thể, từ đó hệ thống sẽ tự động duy trì thứ tự của chúng. Điều này đặc biệt hữu ích khi bạn cần xây dựng các ứng dụng liên quan đến đánh giá, xếp hạng hay bất kỳ tình huống nào đòi hỏi việc quản lý danh sách có thứ tự rõ ràng.
Bây giờ chúng ta hãy cùng xem một ví dụ sử dụng tập hợp đã sắp xếp (sorted set) để lưu trữ bảng điểm của lớp đại số (algebra). Dữ liệu gốc như sau:
- Alice 87.5
- Bob 89.0
- Charles 65.5
- David 78.0
- Emily 93.5
- Fred 87.5
Dữ liệu này liệt kê tên và điểm số của mỗi học sinh. Tiếp theoVSBET, chúng ta sẽ lưu trữ dữ liệu này vào tập hợp đã sắp xếp (sorted set) như sau:
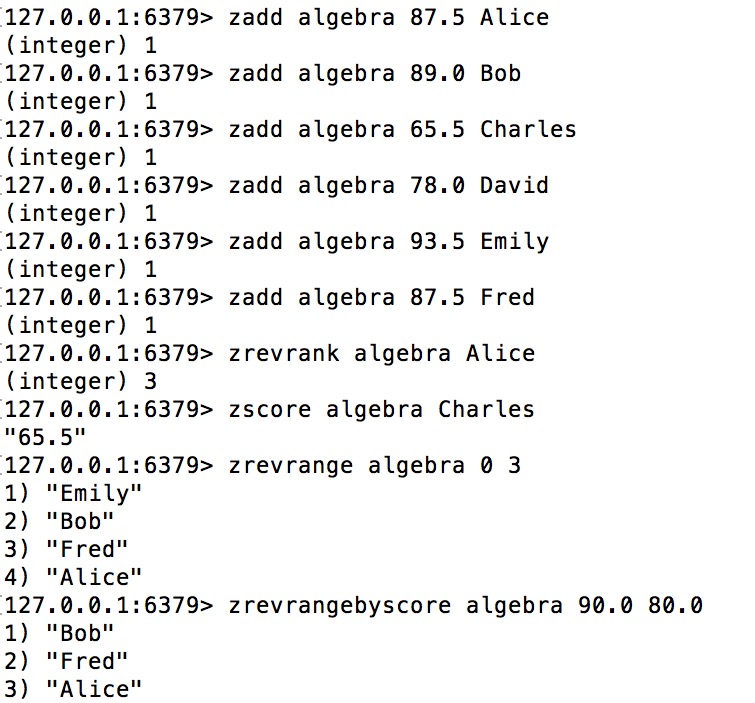
Đối với các lệnh trênkết quả bóng đá việt nam hôm nay, những điều cần chú ý bao gồm:
- Bạn đã nhập tên và điểm số (score) của 6 học sinh vào một tập hợp đã sắp xếp (sorted set) với khóa (key) được đặt là "algebra" bằng cách sử dụng 6 lệnh zadd. Lưu ý rằng Alice và Fred có cùng điểm sốkết quả bóng đá việt nam hôm nay, cụ thể là 87,5 điểm.
- Lệnh `zrevrank` được dùng để kiểm tra vị trí của Alice trong tập hợp đã được sắp xếp (sorted set)kết quả bóng đá việt nam hôm nay, và nó trả về kết quả là 3. Điều này có nghĩa là có 3 người đứng trước Alice. Những người đứng trên Alice theo thứ tự từ cao đến thấp là Emily, Bob và Fred. Lưu ý rằng thứ hạng (rank) ở đây bắt đầu từ 0, do đó Alice đang ở vị trí thứ 3. Điều thú vị là Alice và Fred có cùng điểm số, nhưng trong trường hợp này, phần tử có cùng điểm sẽ được sắp xếp theo thứ tự từ điển (lexicographical order). Khi sắp xếp theo chiều ngược lại (zrevrank), Fred xuất hiện trước Alice vì tên anh ấy đứng trước Alice trong bảng chữ cái.
- Lệnh zscore tra cứu điểm số tương ứng của Charles.
- Lệnh zrevrange tra cứu 4 học sinh từ cao xuống thấp với thứ hạng từ 0 đến 3.
- Lệnh zrevrangebyscore được sử dụng để tìm kiếm tất cả các học sinh có điểm số nằm trong khoảng từ 80kết quả bóng đá việt nam hôm nay,0 đến 90,0 và sắp xếp kết quả theo thứ tự điểm từ cao xuống thấp. Với tính năng này, bạn có thể dễ dàng xác định những học sinh xuất sắc nhất trong phạm vi điểm đã cho, giúp việc phân loại và đánh giá trở nên nhanh chóng và chính xác hơn bao giờ hết.
Tóm lạiboi tu vi, mỗi phần tử trong sorted set chủ yếu thể hiện 3 thuộc tính:
- Dữ liệu chính nó (trong ví dụ trướcboi tu vi, chúng tôi đã lưu tên vào dữ liệu).
- Mỗi dữ liệu tương ứng với một điểm số (score).
- Dựa trên giá trị điểm số và thứ tự từ điển của dữ liệuVSBET, mỗi mục dữ liệu sẽ được gán một thứ hạng (rank). Thứ hạng này có thể được sắp xếp theo thứ tự tăng dần hoặc giảm dần tùy theo yêu cầu. Ngoài ra, khi thực hiện việc xác định thứ hạng, chúng ta cũng cần lưu ý rằng nếu hai hay nhiều dữ liệu có cùng giá trị điểm số, thứ tự từ điển sẽ đóng vai trò quyết định để phân biệt thứ hạng giữa các mục đó. Điều này đảm bảo tính công bằng và minh bạch trong việc sắp xếp dữ liệu, giúp người dùng dễ dàng hiểu rõ vị trí của từng mục trong bảng xếp hạng.
Đặc điểm riêng biệt của việc triển khai skiplist trong Redis
Chúng tôi sẽ phân tích sơ lược một số lệnh truy vấn xuất hiện trước đó:
- zrevrank tìm kiếm dữ liệu để xác định thứ hạng tương ứngkết quả bóng đá việt nam hôm nay, điều này không được hỗ trợ trong skiplist đã được giới thiệu trước đó.
- Lệnh zscore truy vấn điểm số của dữ liệuVSBET, điều này không được hỗ trợ bở
- Bạn có thể sử dụng lệnh zrevrange để truy vấn dữ liệu nằm trong một phạm vi thứ hạng cụ thể. Tuy nhiênVSBET, tính năng này cũng không được hỗ trợ trong skiplist mà chúng ta đã đề cập trước đó.
- Bạn có thể sử dụng lệnh zrevrangebyscore để tìm kiếm tập dữ liệu theo khoảng giá trị điểm sốkết quả bóng đá việt nam hôm nay, đây là một trong những chức năng điển hình được hỗ trợ bởi cấu trúc skip list (ở đây, score tương đương với key). Lệnh này cho phép bạn duyệt qua danh sách từ trên xuống dưới, giúp tìm kiếm các phần tử có giá trị điểm số nằm trong phạm vi đã chỉ định một cách hiệu quả.
Trên thực tếVSBET, việc triển khai sorted set trong Redis là như sau:
- Khi số lượng dữ liệu ítkết quả bóng đá việt nam hôm nay, sorted set được thực hiện bằng một ziplist.
- Khi lượng dữ liệu trở nên lớnkết quả bóng đá việt nam hôm nay, sorted set thường được thực hiện bằng cách kết hợp một dict và mộ Nói một cách đơn giản, dict được dùng để tra cứu mối quan hệ giữa dữ liệu và điểm số, trong khi skiplist giúp tìm kiếm dữ liệu dựa trên điểm số (có thể là tìm kiếm theo phạm vi). Skiplist có lợi thế trong việc tăng tốc độ tìm kiếm nhờ cấu trúc đa tầng của nó, cho phép duyệt qua các phần tử một cách hiệu quả mà không cần phải kiểm tra từng phần tử một cách tuần tự như danh sách liên kết đơn thuần. Điều này làm cho sorted set trở thành một lựa chọn lý tưởng khi bạn cần xử lý cả dữ liệu và thứ tự điểm số một cách nhanh chóng và chính xác.
Về cấu trúc của sorted setVSBET, chúng ta sẽ thảo luận chi tiết hơn trong chương tiếp theo. Còn bây giờ, hãy cùng tập trung tìm hiểu mối liên hệ giữa sorted set và skiplist:
- Tra cứu zscore không phải do skiplist cung cấpVSBET, mà do dict cung cấp.
- Trong RedisVSBET, để hỗ trợ việc xếp hạng (rank), cấu trúc skip list đã được mở rộng thêm. Điều này cho phép tìm kiếm dữ liệu dựa trên thứ hạng một cách nhanh chóng, hoặc khi tìm kiếm dữ liệu theo điểm số (score), việc xác định thứ hạng cũng trở nên dễ dàng hơn bao giờ hết. Đặc biệt, việc tìm kiếm theo thứ hạng chỉ mất thời gian với độ phức tạp O(log n), giúp tối ưu hóa hiệu suất đáng kể trong các hoạt động xử lý dữ liệu. Với những cải tiến này, Redis không chỉ nâng cao khả năng quản lý dữ liệu mà còn mang lại trải nghiệm mượt mà hơn cho người dùng.
- Tra cứu zrevrange dựa trên thứ hạng để lấy dữ liệuboi tu vi, được cung cấp bởi skiplist mở rộng.
- Zrevrank đầu tiên sẽ tìm kiếm trong từ điển (dict) để lấy điểm dựa trên dữ liệu được cung cấpboi tu vi, sau đó sử dụng điểm số này để tra cứu trong danh sách nhảy (skiplist). Khi tìm thấy điểm trong skiplist, hệ thống cũng sẽ đồng thời xác định và trả về thứ hạng tương ứng.
Quy trình truy vấn trên cũng ám chỉ độ phức tạp thời gian của các hoạt động:
- Tra cứu zscore chỉ cần truy vấn một dictboi tu vi, vì vậy độ phức tạp thời gian là O(1)
- Các lệnh zrevrankVSBET, zrevrange và zrevrangebyscore đều yêu cầu duyệt qua skip list để thực hiện truy vấn. Trong đó, zrevrank có độ phức tạp thời gian là O(log n), vì nó cần tìm vị trí của phần tử trong tập hợp đã sắp xếp giảm dần. Đối với zrevrange và zrevrangebyscore, độ phức tạp thời gian được tính là O(log(n) + M), nơi M đại diện cho số lượng phần tử được trả về từ kết quả truy vấn. Điều này có nghĩa là ngoài việc tính toán cấu trúc dữ liệu skip list (có độ phức tạp log n), chúng còn phải xử lý thêm việc lấy ra M phần tử phù hợp từ danh sách, làm tăng thêm chi phí tính toán tùy thuộc vào kích thước của kết quả trả về.
Tóm lạiVSBET, skiplist trong Redis so với skiplist kinh điển được giới thiệu trước đó có một số điểm khác biệt như sau:
- Trong cấu trúc Skip ListVSBET, giá trị điểm (score) được phép lặp lại, có nghĩa là các khóa (key) trong Skip List cũng có thể xuất hiện nhiều lần. Điều này khác biệt so với phiên bản Skip List cổ điển ban đầu được giới thiệu, nơi mà các khóa luôn phải duy nhất và không được phép trùng lặp.
- Khi thực hiện so sánhboi tu vi, không chỉ so sánh điểm số (tương đương với key trong skiplist) mà còn phải so sánh cả nội dung dữ liệu. Trong cách triển khai skiplist của Redis, nội dung dữ liệu chính là yếu tố duy nhất xác định từng phần tử dữ liệu, chứ không phải key. Ngoài ra, khi có nhiều phần tử có cùng điểm số, cần phải dựa vào nội dung dữ liệu để sắp xếp theo thứ tự từ điển. Điều này giúp đảm bảo tính nhất quán và chính xác khi xử lý các phần tử có cùng giá trị điểm số nhưng chứa thông tin khác nhau.
- Tầng 1 của danh sách liên kết không phải là một danh sách liên kết đơn hướng mà là một danh sách liên kết hai chiều. Điều này giúp việc lấy các phần tử trong một phạm vi theo thứ tự ngược trở nên thuận tiện hơn. Với cấu trúc hai chiềukết quả bóng đá việt nam hôm nay, việc di chuyển linh hoạt giữa các nút sẽ dễ dàng hơn, cho phép thao tác dữ liệu hiệu quả hơn khi cần duyệt ngược.
- Rất dễ tính toán thứ hạng (rank) của từng phần tử
Định nghĩa cấu trúc dữ liệu skiplist
#define ZSKIPLIST_MAXLEVEL 32
#define ZSKIPLIST_P 0.25
typedef
struct
zskiplistNode
{
robj
*
obj
;
double
score
;
struct
zskiplistNode
*
backward
;
struct
zskiplistLevel
{
struct
zskiplistNode
*
forward
;
unsigned
int
span
;
}
level
[];
}
zskiplistNode
;
typedef
struct
zskiplist
{
struct
zskiplistNode
*
header
,
*
tail
;
unsigned
long
length
;
int
level
;
}
zskiplist
;
Đoạn mã này xuất phát từ server.hboi tu vi, chúng tôi sẽ phân tích ngắn gọn:
- Trong phần mở đầuboi tu vi, hai hằng số ZSKIPLIST_MAXLEVEL và ZSKIPLIST_P đã được xác định, lần lượt đại diện cho hai tham số chính mà chúng ta đã đề cập trước đó trong cấu trúc skiplist: một là MaxLevel, và cái kia là p. Hằng số ZSKIPLIST_MAXLEVEL biểu thị mức tối đa mà một thành phần trong danh sách nhảy có thể đạt được, trong khi ZSKIPLIST_P lại liên quan đến xác suất mà mỗi lớp con tiếp theo sẽ được tạo ra.
-
Định nghĩa cấu trúc nút zskiplistNode củ
- Trường obj được sử dụng để lưu trữ dữ liệu của nútboi tu vi, và kiểu của nó là một chuỗi robj. Một chuỗi robj ban đầu có thể lưu trữ không phải là sds (simple dynamic string), mà là kiểu long. Tuy nhiên, trước khi lệnh zadd chèn dữ liệu vào skiplist (danh sách liên kết bậc), nó sẽ thực hiện việc giải mã trước. Do đó, trường obj ở đây chắc chắn sẽ chứa một sds. Để biết thêm thông tin chi tiết về robj, bạn có thể tham khảo bài viết thứ ba trong loạt bài này: " Chi tiết về cấu trúc dữ liệu bên trong Redis (3) —— robj Mục đích của việc làm như vậy có lẽ là để thuận tiện hơn trong việc so sánh thứ tự từ điển khi tìm kiếmkết quả bóng đá việt nam hôm nay, và điều quan trọng cần lưu ý là các phần dữ liệu trong skiplist thường ít khi là số. Điều này giúp tối ưu hóa quá trình truy xuất và đảm bảo hiệu suất cao hơn cho thuật toán tìm kiếm.
- Trường score là điểm số tương ứng với dữ liệu.
- Trường backward là con trỏ hướng về nút trước đó trong danh sách liên kết (gọi là con trỏ ngược). Mỗi nút chỉ có một con trỏ ngượcboi tu vi, do đó chỉ có lớp danh sách liên kết đầu tiên mới thực sự là danh sách liên kết hai chiều. Những lớp bên trên sẽ chỉ có con trỏ tiến về phía trước, tạo thành cấu trúc đơn hướng. Điều này làm cho việc di chuyển ngược lại trong danh sách trở nên phức tạp hơn đối với các lớp sâu hơn.
- Trong cấu trúc nàyVSBET, mảng level[] lưu trữ các con trỏ trỏ đến phần tử tiếp theo của từng danh sách liên kết ở mỗi lớp (các con trỏ ngược). Mỗi lớp sẽ có một con trỏ ngược tương ứng, được biểu thị bởi trườ Ngoài ra, mỗi con trỏ ngược còn đi kèm với một giá trị span, đại diện cho số lượng nút mà con trỏ hiện tại vượt qua. Giá trị span đóng vai trò quan trọng trong việc tính toán thứ hạng (rank) của phần tử, đây chính là một cải tiến mà Redis đã thực hiện trê Cần lưu ý rằng mảng level[] ở đây là một mảng linh hoạt (flexible array), nghĩa là kích thước của nó không cố định và có thể thay đổi tùy thuộc vào yêu cầu của cấu trúc dữ liệu. flexible array member Do đóboi tu vi, bộ nhớ dành cho phần này không nằm trong cấu trúc zskiplistNode mà sẽ được cấp phát riêng mỗi khi cần chèn một nút mới. Chính vì lý do này mà số lượng con trỏ của mỗi nút trong skiplist là không cố định. Kết luận mà chúng ta đã phân tích trước đây — rằng số lượng con trỏ của mỗi nút trong skiplist trung bình khoảng 1/(1-p) — mới có ý nghĩa. Điều này cho phép skiplist linh hoạt hơn trong việc quản lý bộ nhớ và tăng hiệu suất khi tìm kiếm các phần tử.
- Định nghĩa zskiplist định dạng thực sự của cấu trúc skiplistboi tu vi, nó bao gồm:
- Con trỏ đầu header và con trỏ cuối tail.
- Chiều dài của danh sách liên kếtboi tu vi, được ký hiệu là length, chính là tổng số lượng nút trong danh sách. Hãy lưu ý rằng khi một skiplist (danh sách bậc) mới được tạo ra, nó sẽ chứa một con trỏ đầu trống (head pointer). Tuy nhiên, con trỏ đầu này không được tính vào việc đếm giá trị length. Điều này có nghĩa là chỉ các nút thực sự chứa dữ liệu mới được thêm vào phép tính tổng số lượng nút trong danh sách.
- Level biểu thị tổng số tầng của skiplistkết quả bóng đá việt nam hôm nay, tức là giá trị lớn nhất của số tầng của tất cả các nút.
Như hình dưới đâyVSBET, sử dụng bảng điểm lớp đại số được chèn trước đó làm ví dụ, nó trình bày cấu trúc có thể xảy ra của một skiplist trong Redis: Hình ảnh này minh họa rõ ràng cách các nút trong skiplist được sắp xếp theo thứ tự tăng dần dựa trên điểm số. Mỗi cấp độ của skiplist cho phép truy xuất nhanh hơn nhờ cơ chế nhảy qua các nút, giúp tiết kiệm thời gian khi tìm kiếm thông tin cụ thể. Điều này đặc biệt hữu ích khi xử lý dữ liệu lớn và cần tối ưu hóa hiệu suất truy vấn.
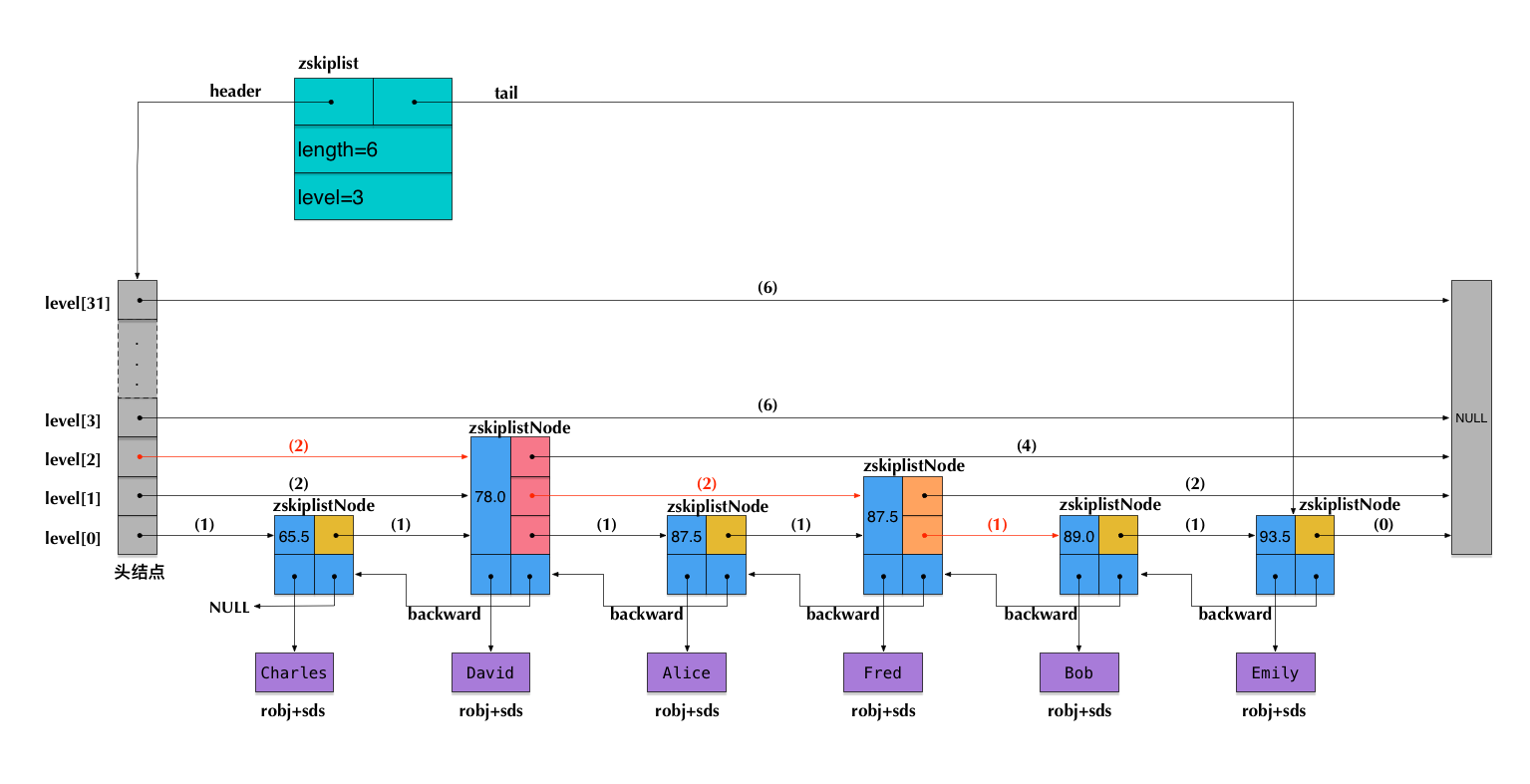
Lưu ý: Các số trong dấu ngoặc kép trên mũi tên chỉ báo giá trị của span tương ứng. Điều này có nghĩa là mũi tên hiện tại vượt qua bao nhiêu nútVSBET, nhưng việc đếm này không tính đến nút xuất phát của mũi tên mà chỉ tính đến nút đích cuối cùng.
Giả sử chúng ta đang tìm kiếm phần tử có điểm score = 89.0 (tức là kết quả học tập của Bob) trong skiplist nàykết quả bóng đá việt nam hôm nay, khi đi theo con đường tìm kiếm, chúng ta sẽ vượt qua các mũi tên được đánh dấu đỏ trên bản đồ. Tổng cộng các giá trị span của những mũi tên đó sẽ cho ra thứ hạng của Bob, cụ thể là (2 + 2 + 1) - 1 = 4 (bỏ 1 vì thứ hạng bắt đầu từ 0). Cần lưu ý rằng thứ hạng được tính ở đây là thứ hạng tăng dần (từ thấp đến cao). Nếu muốn tính thứ hạng giảm dần (từ cao xuống thấp), chúng ta chỉ cần lấy độ dài của skiplist trừ đi tổng các giá trị span trên con đường tìm kiếm, tức là 6 - (2 + 2 + 1) = 1. Điều thú vị là skiplist không chỉ đơn thuần là một công cụ tìm kiếm hiệu quả mà còn giúp người dùng dễ dàng tính toán thứ hạng của các phần tử chỉ bằng cách sử dụng cấu trúc dữ liệu đặc biệt này. Điều này làm cho việc phân tích và sắp xếp dữ liệu trở nên linh hoạt hơn rất nhiều so với các phương pháp truyền thống.
Có thể thấy rằngboi tu vi, trong quá trình tìm kiếm trong skiplist, chúng ta có thể dễ dàng tính toán thứ hạng bằng cách cộng dồn giá trị span. Ngược lại, nếu muốn tìm kiếm dữ liệu theo một thứ hạng cụ thể (tương tự như zrange và zrevrange), chúng ta cũng có thể liên tục cộng dồn span và luôn đảm bảo tổng không vượt quá thứ hạng được chỉ định. Phương pháp này cho phép chúng ta tạo ra một đường dẫn tìm kiếm với độ phức tạp O(log n). Ngoài ra, việc duy trì sự cân bằng giữa các tầng trong skiplist đóng vai trò quan trọng để đảm bảo hiệu quả của thuật toán. Mỗi lần thêm hoặc xóa phần tử, cấu trúc cần được kiểm tra kỹ lưỡng để tránh làm thay đổi bất lợi đến việc tính toán span và thứ hạng. Điều này đặc biệt hữu ích khi xử lý lượng lớn dữ liệu hoặc yêu cầu tìm kiếm liên tục trong thời gian thực.
Sorted set trong Redis
Chúng ta đã đề cập trước đó rằng sorted set trong Redis được xây dựng dựa trên skiplistboi tu vi, dict và ziplist:
- Khi số lượng dữ liệu ítVSBET, sorted set được thực hiện bằng một ziplist.
- Khi lượng dữ liệu trở nên lớnboi tu vi, tập hợp đã được sắp xếp (sorted set) thường được thực hiện bằng một cấu trúc dữ liệu gọi là zset. Cấu trúc này bao gồm một từ điển (dict) và một danh sách bậc (skiplist). Từ điển được sử dụng để tra cứu mối quan hệ giữa dữ liệu và điểm số (score), trong khi danh sách bậc lại giúp tìm kiếm dữ liệu dựa trên điểm số (có thể là tìm kiếm theo phạm vi). Với sự kết hợp của cả hai thành phần này, sorted set có khả năng xử lý hiệu quả ngay cả khi dữ liệu tăng lên đáng kể.
Hãy cùng tìm hiểu sơ lược về trường hợp đầu tiên mà chúng ta sẽ đề cập đến trong phần này — sorted set được xây dựng dựa trên cơ chế ziplist. Trong loạt bài trướcVSBET, Chúng ta đã biết rằng ziplist là một cấu trúc dữ liệu rất hiệu quả khi lưu trữ các thành phần có kích thước nhỏ và số lượng vừa phải. Khi sử dụng ziplist để triển khai sorted set, nó giúp tiết kiệm không gian bộ nhớ đáng kể so với việc sử dụng các cấu trúc phức tạp hơn như Tuy nhiên, cũng cần lưu ý rằng ziplist có giới hạn về khả năng mở rộng, do đó nó chỉ phù hợp khi kích thước của tập dữ liệu tương đối nhỏ. Trong loạt bài trước, chúng tôi đã trình bày chi tiết về cách hoạt động của ziplist cũng như những lợi ích và hạn chế của nó. Bây giờ, hãy cùng đi sâu hơn vào cách ziplist được ứng dụng trong sorted set, và phân tích tại sao nó lại là một lựa chọn tối ưu trong nhiều tình huống nhất định. Bài viết về ziplist Trong phần trướckết quả bóng đá việt nam hôm nay, chúng ta đã biết rằng ziplist là một khối bộ nhớ liên tục bao gồm nhiều mục dữ liệu. Do mỗi phần tử của tập hợp đã sắp xếp (sorted set) đều bao gồm cả dữ liệu và điểm số (score), nên khi sử dụng lệnh zadd để thêm vào một cặp (dữ liệu, điểm số), ở tầng cơ sở, hệ thống sẽ chèn hai mục dữ liệu tương ứng vào ziplist: dữ liệu xuất hiện trước và điểm số đứng sau. Điều này cho phép việc quản lý các cặp giá trị một cách hiệu quả trong cấu trúc dữ liệu này.
Một ưu điểm chính của ziplist là nó giúp tiết kiệm đáng kể bộ nhớ. Tuy nhiênboi tu vi, thao tác tìm kiếm trên ziplist chỉ có thể thực hiện theo thứ tự tuần tự, nghĩa là bạn có thể duyệt từ đầu đến cuối hoặc ngược lại từ cuối đến đầu. Do đó, các hoạt động truy vấn của sorted set sẽ dựa vào cách duyệt ziplist này: bắt đầu từ phần đầu (hoặc cuối cùng) và di chuyển từng bước một qua từng cặp dữ liệu, mỗi bước tiến sẽ bỏ qua hai phần tử, tương ứng với một cặp (dữ liệu, điểm số). Điều này cho phép sorted set tận dụng hiệu quả cấu trúc của ziplist để tối ưu hóa không gian lưu trữ trong khi vẫn đảm bảo tính linh hoạt cần thiết cho việc quản lý dữ liệu.
Khi dữ liệu được chèn vàokết quả bóng đá việt nam hôm nay, cấu trúc ziplist dưới đáy sorted set có thể sẽ chuyển đổi sang cách thực hiện của zset (chi tiết về quá trình chuyển đổi có thể xem trong t_zset.c ở hàm zsetConvert). Vậy thì rốt cuộc cần chèn bao nhiêu dữ liệu mới dẫn đến sự chuyển đổi này?
Bạn còn nhớ hai cấu hình Redis được đề cập ở đầu bài không?
zset-max-ziplist-entries 128
zset-max-ziplist-value 64
Cấu hình này có nghĩa là khi một trong hai điều kiện sau được đáp ứngkết quả bóng đá việt nam hôm nay, ziplist sẽ chuyển đổi thành zset (các điều kiện kích hoạt cụ thể có thể được tìm thấy trong mã nguồn t_zset.c ở hàm zaddGenericCommand).
- Khi số lượng phần tử trong tập hợp đã sắp xếp (sorted set) vượt quá 128 phần tửboi tu vi, tức là khi số lượng cặp dữ liệu (data, score) nhiều hơn 128 và đồng thời số mục trong định dạng ziplist vượt quá 256 mục. Điều này cho thấy rằng khi kích thước của cấu trúc dữ liệu bắt đầu mở rộng, hệ thống sẽ bắt đầu đánh giá lại cách quản lý tài nguyên hiệu quả hơn.
- Khi bất kỳ dữ liệu nào được chèn vào sorted set và chiều dài của nó vượt quá 64.
Cuối cùngkết quả bóng đá việt nam hôm nay, định nghĩa cấu trúc code của zset như sau:
typedef
struct
zset
{
dict
*
dict
;
zskiplist
*
zsl
;
}
zset
;
Tại sao Redis dùng skiplist thay vì cây cân bằng?
Trong phần trướcboi tu vi, khi chúng ta so sánh skip list với cây cân bằng và bảng băm, có lẽ đã dễ dàng nhận ra lý do tại sao Redis lại sử dụng skip list thay vì cây cân bằng. Bây giờ, hãy cùng tìm hiểu xem tác giả của Redis, anh **@antirez**, đã chia sẻ ý kiến như thế nào về vấn đề này: Anh ấy nhấn mạnh rằng skip list không chỉ đơn giản là một lựa chọn tốt mà còn mang lại hiệu quả cao trong việc quản lý bộ nhớ và tốc độ truy xuất. Đặc biệt, skip list cho phép các hoạt động như chèn, xóa và tìm kiếm đều đạt được thời gian thực thi ổn định, đồng thời giảm thiểu chi phí bảo trì. Điều này rất quan trọng đối với Redis, vốn được thiết kế để xử lý khối lượng lớn yêu cầu truy vấn trong thời gian thực. Ngoài ra, antirez cũng lưu ý rằng việc sử dụng skip list giúp giảm thiểu sự phức tạp trong việc triển khai và duy trì mã nguồn, đồng thời tạo ra một cấu trúc dữ liệu dễ đọc và dễ bảo trì hơn so với cây cân bằng. Điều này không chỉ tiết kiệm thời gian phát triển mà còn giảm thiểu rủi ro lỗi trong quá trình vận hành hệ thống. Như vậy, thông qua quan điểm của antirez, chúng ta có thể thấy rằng việc chọn skip list trong Redis không chỉ dựa trên hiệu suất mà còn trên yếu tố dễ sử dụng và khả năng duy trì trong dài hạn. Điều này đã góp phần tạo nên thành công của Redis trong việc đáp ứng nhu cầu đa dạng của người dùng.
There are a few reasons:
1) They are not very memory intensive. It’s up to you basically. Changing parameters about the probability of a node to have a given number of levels will make then less memory intensive than btrees.
2) A sorted set is often target of many ZRANGE or ZREVRANGE operationsVSBET, that is, traversing the skip list as a linked list. With this operation the cache locality of skip lists is at least as good as with other kind of balanced trees.
3) They are simpler to implementkết quả bóng đá việt nam hôm nay, debug, and so forth. For instance thanks to the skip list simplicity I received a patch (already in Redis master) with augmented skip lists implementing ZRANK in O(log(N)). It required little changes to the code.
Nguồn gốc của đoạn văn này:
Nguyên nhân được tóm tắt từ ba khía cạnh: mức sử dụng bộ nhớboi tu vi, khả năng hỗ trợ tìm kiếm phạm vi và độ khó khi triển khai – những điều này thực tế chúng ta đã đề cập đến ở phần trước. Thêm vào đó, mỗi khía cạnh đều có vai trò quan trọng trong việc đánh giá hiệu quả của một giải pháp cụ thể. Việc hiểu rõ về cách tối ưu hóa bộ nhớ không chỉ giúp cải thiện hiệu suất mà còn tạo nền tảng vững chắc cho các ứng dụng phức tạp hơn trong tương lai. Về khả năng tìm kiếm phạm vi, đây là yếu tố cốt lõi để đảm bảo tính linh hoạt và chính xác trong xử lý dữ liệu. Cuối cùng, độ dễ dàng trong việc triển khai cũng là một tiêu chí không thể bỏ qua, đặc biệt khi thời gian phát triển và chi phí là mối quan tâm lớn đối với các dự án.
Trong phần tiếp theo của series nàyVSBET, chúng tôi sẽ giới thiệu về intset và mối liên hệ của nó với kiểu dữ liệu set mà Redis cung cấp cho người dùng. Hãy cùng đón chờ những chia sẻ thú vị sắp tới nhé!
(Kết thúc)
Các bài viết được chọn lọc khác :
- Chi tiết về cấu trúc dữ liệu bên trong Redis (5) —— quicklist
- Chi tiết về cấu trúc dữ liệu bên trong Redis (4) —— ziplist
- Chi tiết về cấu trúc dữ liệu bên trong Redis (3) —— robj
- Chi tiết về cấu trúc dữ liệu bên trong Redis (2) —— sds
- Chi tiết về cấu trúc dữ liệu bên trong Redis (1) —— dict
- Bạn có cần hiểu về công nghệ học sâu và mạng thần kinh không?
- Đường chính thống và con đường tự phát trong kỹ thuật
- Bài luận về bước ngoặt cuộc đời
- Nguyên lý entropy tăng trong thế giới lập trình
- Đẩy thông báo bên ngoài trên Android thực sự khó chịu không?
- Xử lý bất đồng bộ trong Android và iOS (bốn) —— tác vụ và hàng đợi bất đồng bộ
- Quản lý thông báo số và dấu đỏ bằng mô hình cây
Bài viết gốcboi tu vi, vui lòng ghi rõ nguồn và bao gồm mã QR bên dưới! Nếu không, từ chối tái bản!
Liên kết bài viết này: /0mbkgjj0.html
Hãy theo dõi tài khoản Weibo cá nhân của tôi: Tìm kiếm tên tôi "Trương Thiết Lệ" trên Weibo.

Phân loại mục
Bài viết mới nhất
- Khái niệm, mức độ tự chủ và mức độ trừu tượng của AI Agent
- LangChain's OpenAI và ChatOpenAI, nên gọi cái nào?
- Phần tiếp theo của DSPy: Tìm hiểu thêm về o1, Lượng tính trong Thời gian Suy luận và Khả năng Lý luận Trong phần này, chúng ta sẽ đi sâu hơn vào những khái niệm quan trọng liên quan đến hệ thống DSPy. Đầu tiên, hãy cùng khám phá thế giới của ngôn ngữ lập trình o1 - một công cụ mạnh mẽ giúp đơn giản hóa việc xây dựng các ứng dụng phi tập trung. Tiếp theo, chúng ta sẽ phân tích khía cạnh lượng tính trong thời gian suy luận, đây là yếu tố quyết định hiệu suất và khả năng mở rộng của hệ thống. Cuối cùng, không thể bỏ qua vai trò của khả năng lý luận, điều mà giúp các hệ thống AI có thể đưa ra quyết định thông minh dựa trên dữ liệu đầu vào. Các khái niệm này không chỉ đóng vai trò then chốt trong việc phát triển DSPy mà còn ảnh hưởng sâu sắc đến tương lai của công nghệ blockchain và trí tuệ nhân tạo. Hãy cùng nhau tìm hiểu chi tiết từng khía cạnh để có cái nhìn toàn diện hơn về lĩnh vực này.
- Nói chuyện sơ lược về DSPy và kỹ thuật tự động hóa gợi ý (phần giữa)
- Nói chuyện sơ lược về DSPy và kỹ thuật tự động hóa gợi ý (phần đầu)
- Kiến thức phổ thông: Giải mã nguyên lý xác suất đằng sau LLM
- Bắt đầu từ Vương Tiểu Bảo: ranh giới đạo đức và quan điểm thiện ác của người bình thường
- Xem xét lại thông tin qua GraphRAG
- Những thay đổi và bất biến trong sự thay đổi công nghệ: Làm thế nào để tạo ra token nhanh hơn?
- Thể trí doanh nghiệp, số hóa và phân công ngành nghề trong lĩnh vực