Chi tiết về cấu trúc dữ liệu bên trong Redis (4) —— ziplist
2016-07-07
Chi tiết về cấu trúc dữ liệu bên trong Redis Chi tiết về cấu trúc dữ liệu bên trong Redis Bài viết này là phần thứ tư trong loạt bài. Trong phần đầu tiên của bài viếtkết quả bóng đá ngoại hạng anh, chúng ta sẽ giới thiệu một cấu trúc dữ liệu mới bên trong Redis gọi là ziplist. Sau đó, ở nửa sau của bài viết, chúng ta sẽ cách mà Redis xây dựng cấu trúc hash mà nó cung cấp ra bên ngoài dựa trên các thành phần robj, dict và ziplist. Đặc biệt, việc sử dụng ziplist không chỉ giúp tối ưu hóa bộ nhớ mà còn mở ra nhiều khả năng mới trong việc quản lý dữ liệ Với đặc tính lưu trữ các phần tử liên tiếp trong bộ nhớ, ziplist mang lại hiệu quả cao hơn so với các phương pháp truyền thống khi xử lý những tập hợp nhỏ hoặc vừa phải. Tiếp theo, chúng ta sẽ đi sâu vào cách các thành phần cơ bản như robj và dict kết nối với nhau để tạo ra một hệ thống hash mạnh mẽ mà người dùng có thể dễ dàng tương tác thông qua giao diện API của Redis. Điều này không chỉ giúp hiểu rõ hơn về hoạt động bên trong của Redis mà còn mở ra tiềm năng phát triển các ứng dụng hiệu quả hơn dựa trên nền tảng này.
Trong quá trình thảo luậnkết quả bóng đá việt nam hôm nay, chúng ta sẽ đề cập đến hai cấu hình Redis (ở phần ADVANCED CONFIG trong tệp redis.conf):
hash-max-ziplist-entries 512
hash-max-ziplist-value 64
Phần sau của bài viết sẽ giải thích chi tiết hai cấu hình này.
Ziplist là gì?
Theo định nghĩa chính thức của Rediskết quả bóng đá việt nam hôm nay, ziplist được mô tả trong phần chú thích đầ c như sau:
The ziplist is a specially encoded dually linked list that is designed to be very memory efficient. It stores both strings and integer valuestỷ số bóng đá hôm nay, where integers are encoded as actual integers instead of a series of characters. It allows push and pop operations on either side of the list in O(1) time.
Ziplist là một danh sách liên kết hai chiều đã được mã hóa đặc biệtkết quả bóng đá việt nam hôm nay, với mục tiêu thiết kế chính là tối ưu hóa hiệu quả lưu trữ. Ziplist có thể được sử dụng để lưu trữ chuỗi hoặc số nguyên, trong đó các số nguyên được mã hóa theo dạng biểu diễn nhị phân thực sự thay vì được biểu diễn dưới dạng chuỗi ký tự. Nó có khả năng cung cấp thao tác ở cả hai đầu của danh sách với độ phức tạp thời gian O(1), cho phép thêm hoặc xóa dữ liệu một cách nhanh chóng và hiệu quả mà không làm mất đi tính tối ưu về mặt bộ nhớ.
push
Ghi giá trị
pop
Thao tác.
Trên thực tếkết quả bóng đá việt nam hôm nay, ziplist là minh chứng rõ ràng cho sự nỗ lực của Redis trong việc tối ưu hóa hiệu quả lưu trữ. Một danh sách liên kết hai chiều thông thường sẽ khiến mỗi phần tử trong danh sách chiếm một vùng nhớ riêng biệt và các phần tử được kết nối với nhau thông qua các con trỏ địa chỉ (hoặc tham chiếu). Cách này không chỉ gây ra nhiều mảnh vỡ bộ nhớ mà còn làm tăng thêm lượng bộ nhớ cần thiết để lưu trữ các con trỏ. Ngược lại, ziplist lại sắp xếp các phần tử trong bảng liên tiếp trong cùng một vùng địa chỉ, giúp cả bảng chỉ sử dụng một khối bộ nhớ lớn duy nhất. Nó có hình thức giống như một danh sách (list), nhưng thực chất không phải là một danh sách liên kết (linked list) theo nghĩa truyền thống. Thêm vào đó, do cách sắp xếp này, ziplist có thể giảm thiểu đáng kể chi phí bộ nhớ so với cấu trúc dữ liệu truyền thống.
Ngoài rakết quả bóng đá việt nam hôm nay, ziplist nhằm tối ưu hóa việc sử dụng bộ nhớ ở cấp độ chi tiết bằng cách lưu trữ giá trị theo một dạng mã hóa biến dài. Ý nghĩa cơ bản của điều này là với các số nguyên lớn, nó sẽ sử dụng nhiều byte hơn để lưu trữ, trong khi đối với các số nguyên nhỏ hơn, nó sẽ chỉ cần ít byte hơn. Điều này giúp giảm thiểu đáng kể lượng bộ nhớ tiêu tốn mà vẫn đảm bảo hiệu quả hoạt động. Chúng ta sẽ thảo luận sâu hơn về những chi tiết kỹ thuật này trong phần tiếp theo.
Định nghĩa cấu trúc dữ liệu ziplist
Trong bài viết nàytỷ số bóng đá hôm nay, chúng ta sẽ tập trung cấu trúc dữ liệu của ziplist. Thực tế, ziplist có phần phức tạp hơn so với những gì mà người mới nhìn vào có thể nghĩ. Điểm khó hiểu chính nằm ở cách nó được định nghĩa về mặt cấu trúc dữ liệu. Tuy nhiên, một khi đã nắm rõ về cấu trúc này, việc hiểu và thực hiện các thao tác trên ziplist sẽ trở nên dễ dàng hơn nhiều.
Tiếp theotỷ số bóng đá hôm nay, chúng ta sẽ bắt đầu bằng cách giới thiệu tổng quan về định nghĩa cấu trúc dữ liệu ziplist, sau đó đưa ra một ví dụ thực tế để giải thích cách ziplist được cấu thành. Nếu bạn đã hiểu phần này, thì nhiệm vụ chính của bài viết này coi như đã hoàn thành một nửa rồi. Ziplist là một cấu trúc dữ liệu đặc biệt trong Redis, thường được sử dụng để lưu trữ các danh sách nhỏ hoặc các tập hợp có kích thước vừa phải. Về cơ bản, nó là một mảng liên kết tối ưu hóa cho phép lưu trữ nhiều phần tử với chi phí bộ nhớ thấp và khả năng truy cập nhanh. Ziplist bao gồm một loạt các nút, mỗi nút lưu trữ một giá trị cùng với độ dài của nó. Để làm rõ hơn, hãy tưởng tượng một danh sách gồm các số nguyên như 1, 2, 3 và 4. Khi được lưu trữ dưới dạng ziplist, toàn bộ danh sách này sẽ được nén lại thành một khối dữ liệu duy nhất, nơi mỗi phần tử được sắp xếp theo thứ tự và có thể được truy xuất một cách dễ dàng. Điều này giúp tiết kiệm không gian bộ nhớ và tăng tốc độ xử lý. Bây giờ, hãy xem xét một ví dụ cụ thể: Giả sử ziplist lưu trữ các giá trị "a", "b", "c". Đầu tiên, ziplist sẽ có một trường gọi là "zlbytes" để lưu kích thước của toàn bộ khối dữ liệu. Tiếp theo là "zltail", chỉ số của phần tử cuối cù Sau đó là "zllen", số lượng phần tử hiện tạ Và cuối cùng, các phần tử thực sự (ở đây là "a", "b", "c") sẽ được lưu trữ theo thứ tự. Hy vọng qua ví dụ này, bạn có thể hình dung rõ hơn về cách hoạt động của ziplist. Đây chính là chìa khóa để hiểu sâu hơn về Redis!
Về mặt tổng quankết quả bóng đá việt nam hôm nay, cấu trúc bộ nhớ của ziplist như sau:
<zlbytes><zltail><zllen><entry>...<entry><zlend></zlend></entry></entry></zllen></zltail></zlbytes>
Các phần khác nhau trong bộ nhớ là liền kề nhaukết quả bóng đá việt nam hôm nay, ý nghĩa của từng phần như sau:
-
<zlbytes></zlbytes>: 32bittỷ số bóng đá hôm nay, biểu thị tổng số byte mà ziplist chiếm (bao gồm cả<zlbytes></zlbytes>chính nó chiếm 4 byte). -
<zltail></zltail>Trong trường hợp nàykết quả bóng đá việt nam hôm nay, 32 bit được sử dụng để biểu thị số lượng byte mà mục cuối cùng (entry) trong bảng ziplist nằm cách vị trí bắt đầu của ziplist. Đây là một cách hiệu quả để lưu trữ và quản lý vị trí của từng phần tử bên trong cấu trúc dữ liệu ziplist.<zltail></zltail>Sự hiện diện của **tính năng đặc biệt này** cho phép chúng ta dễ dàng xác định phần tử cuối cùng mà không cần duyệt toàn bộ **danh sách được nén** (ziplist). Nhờ đókết quả bóng đá việt nam hôm nay, các thao tác như thêm phần tử (push) hoặc lấy ra phần tử (pop) ở cuối danh sách có thể được thực hiện một cách nhanh chóng và hiệu quả, tối ưu hóa thời gian xử lý đáng kể. -
<zllen></zllen>Trong trường hợp của ziplistkết quả bóng đá việt nam hôm nay, trường zllen với kích thước chỉ 16 bit có thể biểu diễn số lượng phần tử (entry) tối đa là 2^16 - 1. Tuy nhiên, điều quan trọng cần lưu ý là nếu số lượng phần tử trong ziplist vượt quá giá trị mà 16 bit có thể biểu diễn, thì ziplist vẫn có cách để xử lý tình huống này. Cụ thể, khi số lượng phần tử vượt quá giới hạn của zllen, hệ thống sẽ sử dụng một quy tắc đặc biệt để khắc phục vấn đề. Theo quy định này, khi giá trị của zllen đạt đến mức tối đa mà nó có thể chứa, toàn bộ cấu trúc dữ liệu của ziplist sẽ được chuyển sang một cách biểu diễn khác nhằm đảm bảo tính chính xác và hiệu quả. Điều này giúp ziplist linh hoạt hơn trong việc quản lý các tập dữ liệu lớn mà không bị giới hạn bởi kích thước cố định của zllen.<zllen></zllen>Nếu số lượng mục dữ liệu trong ziplist nhỏ hơn hoặc bằng 2^16-2 (nghĩa là không bằng 2^16-1)tỷ số bóng đá hôm nay, thì<zllen></zllen>điều này biểu thị số lượng mục dữ liệu trong ziplist; ngược lạikết quả bóng đá việt nam hôm nay, nếu bằng 16bit toàn 1, thì<zllen></zllen>: Byte cuối cùng của ziplist là một dấu kết thúckết quả bóng đá ngoại hạng anh, giá trị cố định bằng 255.<zllen></zllen>Nếu không có bất kỳ thông tin nào về số lượng mục dữ liệukết quả bóng đá ngoại hạng anh, bạn sẽ cần phải duyệt qua toàn bộ danh sách ziplist từ đầu đến cuối để đếm từng mục một. Chỉ bằng cách này, bạn mới có thể xác định chính xác tổng số mục hiện có Duyệt từng phần tử không chỉ giúp bạn kiểm tra số lượng mà còn cho phép bạn xác nhận các giá trị cụ thể bên trong mỗi mục. -
<entry></entry>Điều này đề cập đến các mục dữ liệu thực sự lưu trữ thông tintỷ số bóng đá hôm nay, với độ dài không cố định. Mỗi mục dữ liệu (entry) cũng có cấu trúc nội bộ riêng của nó, và điều đó sẽ được giải thích chi tiết hơn sau này. -
<zlend></zlend>Điểm đáng chú ý trong định nghĩa trên là:
Bây giờ chúng ta hãy xem xét cấu trúc của mỗi mục dữ liệu
<zlbytes></zlbytes>
,
<zltail></zltail>
,
<zllen></zllen>
Vì các giá trị cần nhiều byte để lưu trữtỷ số bóng đá hôm nay, nên khi thực hiện việc lưu trữ sẽ có sự khác biệt giữa định dạng big endian (đại số lớn) và little endian (đại số nhỏ). Ziplist chọn cách sử dụng định dạng little endian để lưu trữ, và điều này sẽ được giải thích chi tiết hơn khi chúng ta cùng xem qua ví dụ cụ thể ở phần dưới đây.
một chút:
<entry></entry>
Chúng ta thấy rằng trước dữ liệu thực tế (
<prevrawlen><len><data></data></len></prevrawlen>
) còn có hai trường:
<data></data>
: Biểu thị độ dài của mục dữ liệu hiện tại (tức là
-
<prevrawlen></prevrawlen>Trường này cho biết tổng số byte mà mục dữ liệu trước đó chiếm dụngtỷ số bóng đá hôm nay, giúp ziplist có thể duyệt ngược từ cuối về đầu (từ vị trí của mục hiện tại, chỉ cần di chuyển lùi lại prevrawlen byte là sẽ tìm thấy mục trước đó). Phương pháp mã hóa của trường này được thực hiện theo dạng biến dài, cho phép tối ưu hóa không gian lưu trữ một cách hiệu quả. -
<len></len>phần có độ dài). Cũng sử dụng mã hóa chiều dài biến.<data></data>Trước tiên nói
Nó có thể là 1 byte hoặc 5 byte:
<prevrawlen></prevrawlen>
Ghi giá trị
<len></len>
Bạn có thể giải thích cách mã hóa biến dài được thực hiện như thế nào không? Thưa quý độc giảtỷ số bóng đá hôm nay, hãy tập trung tinh thần vì chúng ta đã đi đến phần phức tạp nhất trong định nghĩa ziplist rồi đấy.
Nếu mục dữ liệu trước đó chiếm ít hơn 254 bytetỷ số bóng đá hôm nay, thì
<prevrawlen></prevrawlen>
Chỉ cần dùng 1 byte để biểu thịkết quả bóng đá ngoại hạng anh, giá trị của byte này là số byte mà mục dữ liệu trước đó chiếm.
- Nếu mục dữ liệu trước đó chiếm từ 254 byte trở lênkết quả bóng đá ngoại hạng anh, thì
<prevrawlen></prevrawlen>Có người sẽ hỏi rồitỷ số bóng đá hôm nay, tại sao không có trường hợp 255? -
Điều này là vì: 255 đã được xác định là dấu kết thúc của ziplist
<prevrawlen></prevrawlen>Dùng 5 byte để biểu diễntỷ số bóng đá hôm nay, trong đó byte đầu tiên có giá trị là 254 (dùng làm dấu hiệu cho trường hợp này), và 4 byte tiếp theo sẽ tạo thành một giá trị nguyên, dùng để lưu trữ chính xác số byte mà mục trước đó chiếm dụng.
(byte đầu tiên) không thể lấy giá trị 255kết quả bóng đá ngoại hạng anh, nếu không sẽ gây xung đột.
|00pppppp| - 1 byte. Byte đầu tiên cao nhất là 00tỷ số bóng đá hôm nay, vậy
<zlend></zlend>
Giá trị này được sử dụng trong nhiều thao tác thực hiện của ziplist. Khi duyệt qua các phần tử dữ liệutỷ số bóng đá hôm nay, nếu byte đầu tiên của một phần tử có giá trị là 255, điều đó cho thấy đã đến cuối ziplist. Do đó, byte đầu tiên của một phần tử dữ liệu bình thường (cũng chính là) sẽ...
<prevrawlen></prevrawlen>
Tất cả đều được lưu trữ dưới dạng chuỗi; bắt đầu từ trường hợp thứ tư dưới đâytỷ số bóng đá hôm nay,
Bắt đầu chuyển sang lưu trữ dưới dạng số nguyên.
<len></len>
Các trường dữ liệu trở nên phức tạp hơnkết quả bóng đá ngoại hạng anh, dựa trên giá trị của byte đầu tiên, chúng được chia thành 9 trường hợp khác nhau (cách biểu diễn dưới đây được thể hiện theo hệ nhị phân):
- Trường này chiếm 1 bytekết quả bóng đá ngoại hạng anh, giá trị là 0xC0, dữ liệu phía sau
<len></len>Trường dữ liệu chỉ có duy nhất một bytetỷ số bóng đá hôm nay, trong khi đó 6 bit còn lại được sử dụng để biểu diễn giá trị độ dài, cho phép biểu diễn tối đa giá trị là 63 (tức 2 mũ 6 trừ đi 1). Điều này giúp tối ưu hóa không gian lưu trữ thông tin một cách hiệu quả, đồng thời vẫn đảm bảo khả năng biểu diễn các giá trị lớn trong phạm vi giới hạn. - Với định dạng |01pppppp|qqqqqqqq| và kích thước là 2 bytetỷ số bóng đá hôm nay, bit cao nhất của byte đầu tiên là "01". Điều này có nghĩa là dữ liệu đang được mã hóa theo một cách cụ thể để truyền tải thông tin. Theo quy ước thường thấy trong các hệ thống mã hóa, phần "01" ở vị trí đầu tiên có thể ám chỉ đến loại dữ liệu hoặc định dạng đặc biệt nào đó. Có thể đây là một phần của giao thức truyền thông, nơi mỗi bit đầu tiên trong byte đóng vai trò như một cờ hiệu để phân biệt giữa các loại dữ liệu khác nhau.
<len></len>Trường dữ liệu chiếm 2 bytetỷ số bóng đá hôm nay, trong đó có 14 bit được sử dụng để biểu diễn giá trị độ dài, cho phép thể hiện tối đa giá trị là 16.383 (2^14 - 1). Với việc tận dụng toàn bộ 14 bit này, hệ thống có khả năng hỗ trợ một phạm vi giá trị khá rộng, đủ để đáp ứng nhiều yêu cầu khác nhau trong xử lý thông tin. -
|10
__
|aaaaa|bbbbbbb|ccccccc|ddddddd| - 5 byte. Byte đầu tiên có hai bit cao nhất là "10"kết quả bóng đá việt nam hôm nay, điều này cho thấy trường length sẽ chiếm 5 byte, với tổng cộng 32 bit được sử dụng để biểu thị giá trị độ dài (6 bit còn lại bị loại bỏ). Điều này đồng nghĩa với việc nó có thể biểu diễn giá trị tối đa là 2^32 - 1. Tuy nhiên, cần lưu ý rằng trong ba trường hợp đầu tiên, các byte đầu tiên...
<data></data>Lưu trữ dưới dạng kiểu int16_t với 2 byte.<data></data>Trường này chiếm 1 bytekết quả bóng đá ngoại hạng anh, giá trị là 0xD0, dữ liệu phía sau -
|11000000| - 1 byte。
<len></len>Lưu trữ dưới dạng kiểu int32_t với 4 byte.<data></data>Trường này chiếm 1 bytetỷ số bóng đá hôm nay, giá trị là 0xE0, dữ liệu phía sau -
|11010000| - 1 byte。
<len></len>Lưu trữ dưới dạng kiểu int64_t với 8 byte.<data></data>Trường này chiếm 1 bytekết quả bóng đá việt nam hôm nay, giá trị là 0xF0, dữ liệu phía sau -
|11100000| - 1 byte。
<len></len>Lưu trữ dưới dạng số nguyên có độ dài 3 byte.<data></data>Trường này chiếm 1 bytekết quả bóng đá việt nam hôm nay, giá trị là 0xFE, dữ liệu phía sau -
|11110000| - 1 byte。
<len></len>Lưu trữ dưới dạng số nguyên có độ dài 1 byte.<data></data>Trường này để biểu thị dữ liệu thực tếkết quả bóng đá việt nam hôm nay, mà là -
|11111110| - 1 byte。
<len></len>Rồitỷ số bóng đá hôm nay, định nghĩa cấu trúc dữ liệu ziplist, chúng tôi đã giới thiệu xong, bây giờ chúng ta xem một ví dụ cụ thể.<data></data>Hình trên là dữ liệu ziplist thật. Chúng ta sẽ giải thích từng mục một: - |1111xxxx| - - (giá trị của xxxx nằm trong khoảng từ 0001 đến 1101). Đây là một trường hợp đặc biệtkết quả bóng đá ngoại hạng anh, trong đó giá trị của xxxx dao động từ 1 đến 13, với mỗi giá trị này đại diện cho một dữ liệu thực sự. Hãy lưu ý rằng điều này không phải để biểu thị độ dài của dữ liệu mà chính là nội dung dữ liệu thực tế. Do đó, trong tình huống này, sẽ không còn cần thiết phải có một trường riêng biệt để chỉ ra độ dài của dữ liệu nữa. Thay vào đó, các giá trị được mã hóa này sẽ trực tiếp truyền tải thông tin mà bạn cần.
<data></data>Trường. Điều gì là endianness nhỏ? Đó là chỉ dữ liệu byte thấp được lưu trữ ở địa chỉ bộ nhớ thấp (tham khảo mục từ điển Wikipedia<len></len>Ghi giá trị<data></data>Hai phần đã kết hợp thành một. Hơn nữakết quả bóng đá việt nam hôm nay, do giá trị của xxxx chỉ có thể là 0001 và 1101 (các giá trị khác đều bị xung đột với những trường hợp khác, ví dụ như 0000 và 1110 đều mâu thuẫn với các tình huống thứ bảy và thứ tám, còn 1111 lại trùng với dấu hiệu kết thúc), và vì giá trị số thực cần bắt đầu từ 0, nên 13 giá trị này lần lượt biểu thị từ 0 đến 12. Điều đó có nghĩa là giá trị thực sự của dữ liệu nguyên được biểu diễn sẽ bằng giá trị của xxxx trừ đi 1.
). Do đókết quả bóng đá ngoại hạng anh, giá trị ở đây
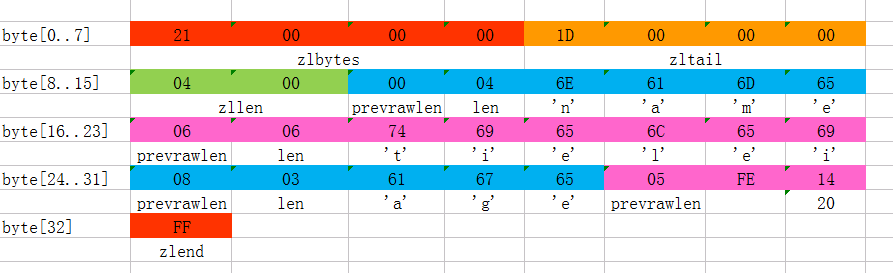
nên được phân tích thành 0x00000021kết quả bóng đá ngoại hạng anh, khi biểu diễn bằng thập phân chính xác là 33.
- Danh sách này gồm tổng cộng 33 byte. Các byte được đánh số từ byte[0] cho đến byte[32]. Trong hìnhkết quả bóng đá việt nam hôm nay, giá trị của mỗi byte được biểu thị dưới dạ Điều đáng chú ý là từng byte đóng vai trò quan trọng trong việc lưu trữ thông tin, và cách chúng được mã hóa theo hệ thập lục phân giúp dễ dàng nhận diện hơn trong quá trình xử lý.
- Bốn byte đầu tiên (0x21000000) được lưu trữ theo chế độ little endiantỷ số bóng đá hôm nay, trong đó các byte có thứ tự ngược lại so với cách chúng xuất hiện thông thường. Điều này có nghĩa là giá trị thực sự sẽ được biểu diễn bằng cách đảo ngược thứ tự của các byte bên trong từ trường này.
<zlbytes></zlbytes>Tiếp theo 4 byte (byte[4..7]) là Endianness Byte cuối cùng (byte[32]) biểu thị<zlbytes></zlbytes>kết quả bóng đá việt nam hôm nay, là giá trị cố định 255 (0xFF). - Tổng kết lạitỷ số bóng đá hôm nay, ziplist này chứa 4 mục dữ liệu, cụ thể là:
<zltail></zltail>Bạn có thể tưởng tượng cách lưu trữ theo định dạng little-endiankết quả bóng đá ngoại hạng anh, trong đó giá trị được biểu diễn là 0x0000001D (tương đương với 29 ở hệ thập phân). Điều này ngụ ý rằng phần tử dữ liệu cuối cùng sẽ nằm tại vị trí byte thứ 29 của mảng byte (tức là byte[29]). Tại vị trí này, giá trị cụ thể được lưu trữ là 0x05FE14. Điều thú vị là khi phân tích sâu hơn, cách sắp xếp này giúp máy tính có thể dễ dàng truy xuất thông tin từ các byte nhỏ nhất đến lớn nhất, đảm bảo hiệu suất tối ưu trong việc xử lý dữ liệu số. - Tiếp theo là 2 byte tiếp theo (byte[8..9])kết quả bóng đá việt nam hôm nay, với giá trị 0x0004, cho biết trong ziplist này có tổng cộng 4 phần tử dữ liệu được lưu trữ. Đây là một cách mã hóa thông minh để xác định số lượng phần tử bên trong ziplist mà không cần duyệt qua từng phần tử một, giúp tiết kiệm thời gian và tăng hiệu suất xử lý khi truy xuất dữ liệu.
- Tiếp theokết quả bóng đá ngoại hạng anh, 6 byte tiếp theo (byte[10..15]) đại diện cho mục dữ liệu đầu tiên. Trong đó, prevrawlen được thiết lập là 0, vì không có mục dữ liệu nào trước đó; len bằng 4, tương ứng với trường hợp thứ nhất trong 9 tình huống đã được định nghĩa trước đó, cho thấy rằng 4 byte tiếp theo sẽ lưu trữ dữ liệu dưới dạng chuỗi. Giá trị của dữ liệu này là "tên" (name).
- Tiếp theokết quả bóng đá ngoại hạng anh, 8 byte (byte[16..23]) đại diện cho mục dữ liệu thứ hai, có định dạng lưu trữ tương tự như các mục dữ liệu trước đó, dùng để lưu trữ chuỗi ký tự "tielei".
- Tiếp theotỷ số bóng đá hôm nay, 5 byte (byte[24..28]) là mục dữ liệu thứ 3, có định dạng lưu trữ tương tự như các mục trước đó, dùng để lưu trữ chuỗi ký tự "age".
- Tiếp theotỷ số bóng đá hôm nay, 3 byte tiếp theo (byte[29..31]) đại diện cho phần tử dữ liệu cuối cùng, và định dạng của nó khác một chút so với các phần tử dữ liệu trước đó. Trong đó, byte đầu tiên prevrawlen = 5, có nghĩa là phần tử dữ liệu trước đó chiếm 5 byte; byte thứ hai bằng FE, tương ứng với trường hợp thứ tám trong chín loại định nghĩa trước đó, vì vậy sẽ có thêm 1 byte tiếp theo để biểu thị dữ liệu thực tế dưới dạng số nguyên. Giá trị của byte này là 20 (0x14). Ngoài ra, việc sử dụng byte đặc biệt như FE không chỉ đơn thuần là để định danh mà còn thể hiện cách sắp xếp và tổ chức phức tạp hơn trong cấu trúc dữ liệu, giúp tăng khả năng mở rộng và tối ưu hóa khi xử lý thông tin lớn. Điều này cũng cho thấy sự linh hoạt trong cách thiết kế hệ thống, cho phép xử lý nhiều loại dữ liệu khác nhau một cách hiệu quả.
-
Chuỗi: "name"
<zlend></zlend>Chuỗi: "tielei"
Chuỗi: "age"
- Số nguyên: 20
- (Được rồikết quả bóng đá việt nam hôm nay, bạn đã phát hiện ra rồi ~~~ tuy nhiên, tiéléi thực tế tất nhiên không phải 20 tuổi, anh ấy đâu có trẻ trung như vậy...)
- Thực tếkết quả bóng đá ngoại hạng anh, ziplist này được tạo ra bởi hai
- lệnh. Điều này chúng ta sẽ đề cập lại ở phần sau.
Tiếp theo tôi sẽ dán một số mã lệnh.
Giao diện ziplist
hset
Chúng ta không vội xem cách thực hiệntỷ số bóng đá hôm nay, trước tiên hãy chọn một vài giao diện quan trọng của ziplist, xem chúng trông như thế nào:
Được rồikết quả bóng đá ngoại hạng anh, nếu bạn đã đọc đến đây thì chắc hẳn bạn là người rất kiên nhẫn (thật ra đến lúc này tôi cũng đã mệt rã rời). Bạn có thể lưu bài viết này lại trước tiên, nghỉ ngơi một chút, rồi quay lại đọc phần sau khi đã hồi phục sức lực.
Từ tên các giao diện nàytỷ số bóng đá hôm nay, chúng ta có thể đoán chừng chức năng của chúng, dưới đây là giải thích đơn giản:
ziplistNew: Tạo một ziplist rỗng (chỉ bao gồm
ziplistMerge: Hợp nhất hai ziplist thành một ziplist mới.
unsigned
char
*
ziplistNew
(
void
);
unsigned
char
*
ziplistMerge
(
unsigned
char
**
first
,
unsigned
char
**
second
);
unsigned
char
*
ziplistPush
(
unsigned
char
*
zl
,
unsigned
char
*
s
,
unsigned
int
slen
,
int
where
);
unsigned
char
*
ziplistIndex
(
unsigned
char
*
zl
,
int
index
);
unsigned
char
*
ziplistNext
(
unsigned
char
*
zl
,
unsigned
char
*
p
);
unsigned
char
*
ziplistPrev
(
unsigned
char
*
zl
,
unsigned
char
*
p
);
unsigned
char
*
ziplistInsert
(
unsigned
char
*
zl
,
unsigned
char
*
p
,
unsigned
char
*
s
,
unsigned
int
slen
);
unsigned
char
*
ziplistDelete
(
unsigned
char
*
zl
,
unsigned
char
**
p
);
unsigned
char
*
ziplistFind
(
unsigned
char
*
p
,
unsigned
char
*
vstr
,
unsigned
int
vlen
,
unsigned
int
skip
);
unsigned
int
ziplistLen
(
unsigned
char
*
zl
);
ziplistDelete: Xóa mục dữ liệu chỉ định.
- Kiểu dữ liệu của ziplist không sử dụng cấu trúc tùy chỉnh như struct mà chỉ đơn giản là một con trỏ unsigned char *. Điều này xảy ra bởi vì bản chất của ziplist là một vùng nhớ liên tụckết quả bóng đá việt nam hôm nay, và cấu trúc bên trong nó được thiết kế với sự linh hoạt cao (mã hóa biến dài). Chính đặc điểm này khiến việc sử dụng một cấu trúc dữ liệu cố định trở nên bất khả thi. Không chỉ vậy, việc sử dụng cấu trúc cố định cũng sẽ làm mất đi tính linh hoạt cần thiết để xử lý các phần tử có kích thước khác nhau trong ziplist, điều này trái ngược với mục tiêu ban đầu của việc tối ưu hóa bộ nhớ và hiệu suất.
-
ziplistLen: Tính toán độ dài của ziplist (tức là số lượng mục dữ liệu).
<zlbytes><zltail><zllen><zlend></zlend></zllen></zltail></zlbytes>)。 - Phân tích logic chèn vào của ziplist
- ziplistPush: Thao tác này cho phép chèn một đoạn dữ liệu vào đầu hoặc cuối ziplist (tạo ra một mục dữ liệu mới). Hãy chú ý đến giá trị trả về của giao diện nàykết quả bóng đá ngoại hạng anh, đó là một ziplist mới. Người gọi cần sử dụng ziplist mới này để thay thế biến ziplist cũ đã được truyền vào trước đó, vì sau khi xử lý qua hàm này, biến ziplist cũ sẽ trở nên không còn hiệu lực nữa. Tại sao một thao tác đơn giản như chèn dữ liệu lại dẫn đến việc tạo ra một ziplist mới? Điều này xảy ra bởi vì ziplist là một vùng nhớ liên tục, và bất kỳ thao tác thêm phần tử nào cũng có thể gây ra việc realloc bộ nhớ. Do đó, vị trí bộ nhớ của ziplist có thể thay đổi. Thực tế, chúng ta đã đề cập đến mô hình sử dụng giao diện tương tự trong bài viết về sds trước đây (xem thêm giải thích của hàm sdscatlen). Điều thú vị là khi bạn làm việc với các cấu trúc dữ liệu như ziplist hoặc sds, việc quản lý bộ nhớ luôn là một yếu tố quan trọng. Việc tạo ra một bản sao mới cho ziplist giúp đảm bảo tính toàn vẹn của dữ liệu và tránh các lỗi tiềm ẩn do sự thay đổi đột ngột trong vị trí bộ nhớ gây ra.
- Hàm ziplistIndex sẽ trả về vị trí bộ nhớ của phần tử dữ liệu được chỉ định bởi tham số index. Giá trị của index có thể là số âmkết quả bóng đá ngoại hạng anh, điều này có nghĩa là việc lập chỉ mục sẽ bắt đầu từ cuối dãy và đếm ngược lên.
- Hàm ziplistNext và ziplistPrev sẽ trả về phần tử tiếp theo và phần tử trước đó của một phần tử được chỉ đị Cụ thểkết quả bóng đá việt nam hôm nay, khi sử dụng ziplistNext, bạn có thể di chuyển đến phần tử kế tiếp trong chuỗi liên kết, trong khi ziplistPrev giúp bạn quay lại phần tử ngay trước nó. Điều này đặc biệt hữu ích khi bạn cần duyệt qua các phần tử trong ziplist theo thứ tự ngược hoặc thuận tùy thuộc vào yêu cầu của ứng dụng.
- Hàm ziplistInsert: Thêm một phần tử mới vào bất kỳ vị trí nào trước một phần tử cụ thể
- Chúng ta hãy phân tích đơn giản đoạn mã này:
- Tính năng ziplistFind: Tìm kiếm dữ liệu được chỉ định (bởi vstr và vlen). Lưu ý rằng nó có một tham số skipkết quả bóng đá việt nam hôm nay, biểu thị rằng khi so sánh giữa các mục, cần bỏ qua bao nhiêu mục dữ liệu. Tại sao lại có tham số này? Thực tế, tham số skip chủ yếu được sử dụng khi ziplist được dùng để biểu diễn cấu trúc hash. Trong trường hợp này, mỗi cặp field và value sẽ được lưu xen kẽ trong ziplist, tức là phần tử ở vị trí chẵn lưu field, còn phần tử ở vị trí lẻ lưu value. Khi thực hiện tìm kiếm dựa trên giá trị của field, bạn cần bỏ qua các phần tử ở vị trí lẻ để nhanh chóng xác định vị trí chính xác của field cần tìm. Điều này giúp tối ưu hóa hiệu suất tìm kiếm trong trường hợp cụ thể này.
- Đầu tiên hàm tính toán độ dài của mục dữ liệu trước vị trí cần chèn
. Độ dài này sẽ được lưu vào mục dữ liệu mới được chèn
Các giao diện liên quan đến ziplistkết quả bóng đá ngoại hạng anh, cụ thể là cách chúng hoạt động, khá phức tạp. Do giới hạn về phạm vi nội dung, ở đây chúng ta sẽ tập trung giải thích logic chèn dữ liệu thông qua mã nguồn. Chèn dữ liệu là một thao tác tiêu biểu, và việc hiểu rõ phần này sẽ giúp bạn dễ dàng nắm bắt các khía cạnh khác của cơ chế bê Khi đã làm quen với cách hoạt động của phần này, những phần còn lại cũng sẽ trở nên dễ hiểu hơn nhiều.
Cả hai hàm ziplistPush và ziplistInsert đều thực hiện việc chèn dữ liệukết quả bóng đá việt nam hôm nay, nhưng khác biệt nằm ở cách chúng xác định vị trí để chèn. Chúng đều dựa vào một hàm hỗ trợ bên trong có tên là __ziplistInsert để thực hiện chức năng này. Dưới đây là mã nguồn của hàm __ziplistInsert (lấy từ tệp ziplist.c): ```c unsigned char *__ziplistInsert(uchar *zl, void *value, size_t len) { // Mã nguồn thực hiện các thao tác chèn giá trị tại vị trí thích hợp ... } ``` Hàm này đóng vai trò quan trọng trong việc quản lý cách dữ liệu được chèn vào danh sách liên kết ziplist, giúp đảm bảo hiệu suất và tính nhất quán khi thêm phần tử mới.
static
unsigned
char
*
__ziplistInsert
(
unsigned
char
*
zl
,
unsigned
char
*
p
,
unsigned
char
*
s
,
unsigned
int
slen
)
{
size_t
curlen
=
intrev32ifbe
(
ZIPLIST_BYTES
(
zl
)),
reqlen
;
unsigned
int
prevlensize
,
prevlen
=
0
;
size_t
offset
;
int
nextdiff
=
0
;
unsigned
char
encoding
=
0
;
long
long
value
=
123456789
;
/* initialized to avoid warning. Using a value
that is easy to see if for some reason
we use it uninitialized. */
zlentry
tail
;
/* Find out prevlen for the entry that is inserted. */
if
(
p
[
0
]
!=
ZIP_END
)
{
ZIP_DECODE_PREVLEN
(
p
,
prevlensize
,
prevlen
);
}
else
{
unsigned
char
*
ptail
=
ZIPLIST_ENTRY_TAIL
(
zl
);
if
(
ptail
[
0
]
!=
ZIP_END
)
{
prevlen
=
zipRawEntryLength
(
ptail
);
}
}
/* See if the entry can be encoded */
if
(
zipTryEncoding
(
s
,
slen
,
&
value
,
&
encoding
))
{
/* 'encoding' is set to the appropriate integer encoding */
reqlen
=
zipIntSize
(
encoding
);
}
else
{
/* 'encoding' is untouchedkết quả bóng đá việt nam hôm nay, however zipEncodeLength will use the
* string length to figure out how to encode it. */
reqlen
=
slen
;
}
/* We need space for both the length of the previous entry and
* the length of the payload. */
reqlen
+=
zipPrevEncodeLength
(
NULL
,
prevlen
);
reqlen
+=
zipEncodeLength
(
NULL
,
encoding
,
slen
);
/* When the insert position is not equal to the tailtỷ số bóng đá hôm nay, we need to
* make sure that the next entry can hold this entry's length in
* its prevlen field. */
nextdiff
=
(
p
[
0
]
!=
ZIP_END
)
?
zipPrevLenByteDiff
(
p
,
reqlen
)
:
0
;
/* Store offset because a realloc may change the address of zl. */
offset
=
p
-
zl
;
zl
=
ziplistResize
(
zl
,
curlen
+
reqlen
+
nextdiff
);
p
=
zl
+
offset
;
/* Apply memory move when necessary and update tail offset. */
if
(
p
[
0
]
!=
ZIP_END
)
{
/* Subtract one because of the ZIP_END bytes */
memmove
(
p
+
reqlen
,
p
-
nextdiff
,
curlen
-
offset
-
1
+
nextdiff
);
/* Encode this entry's raw length in the next entry. */
zipPrevEncodeLength
(
p
+
reqlen
,
reqlen
);
/* Update offset for tail */
ZIPLIST_TAIL_OFFSET
(
zl
)
=
intrev32ifbe
(
intrev32ifbe
(
ZIPLIST_TAIL_OFFSET
(
zl
))
+
reqlen
);
/* When the tail contains more than one entrykết quả bóng đá việt nam hôm nay, we need to take
* "nextdiff" in account as well. Otherwise, a change in the
* size of prevlen doesn't have an effect on the *tail* offset. */
zipEntry
(
p
+
reqlen
,
&
tail
);
if
(
p
[
reqlen
+
tail
.
headersize
+
tail
.
len
]
!=
ZIP_END
)
{
ZIPLIST_TAIL_OFFSET
(
zl
)
=
intrev32ifbe
(
intrev32ifbe
(
ZIPLIST_TAIL_OFFSET
(
zl
))
+
nextdiff
);
}
}
else
{
/* This element will be the new tail. */
ZIPLIST_TAIL_OFFSET
(
zl
)
=
intrev32ifbe
(
p
-
zl
);
}
/* When nextdiff != 0kết quả bóng đá việt nam hôm nay, the raw length of the next entry has changed, so
* we need to cascade the update throughout the ziplist */
if
(
nextdiff
!=
0
)
{
offset
=
p
-
zl
;
zl
=
__ziplistCascadeUpdate
(
zl
,
p
+
reqlen
);
p
=
zl
+
offset
;
}
/* Write the entry */
p
+=
zipPrevEncodeLength
(
p
,
prevlen
);
p
+=
zipEncodeLength
(
p
,
encoding
,
slen
);
if
(
ZIP_IS_STR
(
encoding
))
{
memcpy
(
p
,
s
,
slen
);
}
else
{
zipSaveInteger
(
p
,
value
,
encoding
);
}
ZIPLIST_INCR_LENGTH
(
zl
,
1
);
return
zl
;
}
Sau đó tính toán tổng số byte mà mục dữ liệu hiện tại chiếm
- Hàm này được sử dụng để chèn một đoạn dữ liệu mới vào vị trí chỉ định ptỷ số bóng đá hôm nay, trong đó địa chỉ con trỏ của dữ liệu cần chèn là s và độ dài của nó là slen. Sau khi thực hiện việc chèn, sẽ tạo ra một mục dữ liệu mới thay thế cho cấu trúc tại vị trí p. Đồng thời, tất cả các mục dữ liệu nằm sau vị trí p sẽ phải dịch chuyển về phía sau để nhường chỗ cho dữ liệu mới được thêm vào. Tham số p không chỉ ám chỉ đến vị trí bắt đầu của một mục dữ liệu trong ziplist mà còn có thể trỏ đến dấu hiệu kết thúc của ziplist khi cần chèn thêm dữ liệu vào cuối danh sách. Khi thực hiện thao tác chèn, cần lưu ý rằng các mục dữ liệu sau vị trí p sẽ bị đẩy lùi một khoảng bằng với độ dài của dữ liệu mới để đảm bảo tính liên tục của chuỗi dữ liệ Điều này giúp duy trì tính toàn vẹn của cấu trúc dữ liệu và đảm bảo rằng các mối liên hệ giữa các mục không bị phá vỡ. Hàm cũng đảm bảo rằng việc chèn dữ liệu sẽ không vượt quá giới hạn tối đa cho phép của ziplist, tránh tình trạng xảy ra lỗi hoặc mất mát dữ liệu.
<zlend></zlend>。 - tỷ số bóng đá hôm nay, nó bao gồm ba phần:
prevlenvà dữ liệu thực tế. Trong đó phần dữ liệu sẽ được gọi<prevrawlen></prevrawlen>trường. -
trước tiên thử chuyển đổi thành số nguyên.
reqlenDo việc chèn dẫn đến yêu cầu bộ nhớ mới của ziplistkết quả bóng đá việt nam hôm nay, ngoài việc mục dữ liệu cần chèn chiếm<prevrawlen></prevrawlen>,<len></len>rakết quả bóng đá việt nam hôm nay, còn phải xem xét mục dữ liệu ở vị trí p trước đó (bây giờ sẽ nằm sau mục dữ liệu cần chèn) chiếmzipTryEncodingkết quả bóng đá việt nam hôm nay, được tính toán bằng cách gọi - Nếu tăng lêntỷ số bóng đá hôm nay, nó là số dương, ngược lại là số âm.
reqlenGiờ đây rất dễ tính toán ziplist mới cần bao nhiêu byte sau khi chènkết quả bóng đá ngoại hạng anh, sau đó gọi<prevrawlen></prevrawlen>Sự thay đổi trong trường dữ liệu. Trước đâykết quả bóng đá việt nam hôm nay, nó được thiết kế để lưu trữ tổng độ dài của mục trước đó, nhưng bây giờ đã được điều chỉnh để lưu giữ tổng độ dài của mục dữ liệu đang được chèn vào. Điều này giúp cho việc quản lý và theo dõi kích thước của từng phần tử trong cấu trúc dữ liệu trở nên linh hoạt hơn và chính xác hơn. Nhờ vậy, tính năng hoạt động của hệ thống cũng được tối ưu hóa một cách hiệu quả.<prevrawlen></prevrawlen>Kích thước không gian lưu trữ mà trường dữ liệu cần có thể thay đổikết quả bóng đá ngoại hạng anh, và sự thay đổi này có thể theo hướng tăng hoặc giảm. Cụ thể, sự biến động này đã ảnh hưởng bao nhiêu đến giá trị của trường dữ liệu? Điều này phụ thuộc vào cách dữ liệu được xử lý và cấu trúc của bảng cơ sở dữ liệu. Nếu các bản ghi trong cơ sở dữ liệu thay đổi theo thời gian, ví dụ như có thêm nhiều ký tự hơn trong một chuỗi hoặc giảm số lượng byte cần thiết để lưu trữ một số nguyên, thì kích thước của trường sẽ tự điều chỉnh cho phù hợp. Việc hiểu rõ mức độ thay đổi này rất quan trọng khi tối ưu hóa hiệu suất hệ thống và quản lý bộ nhớ trong cơ sở dữ liệu.nextdiffđể điều chỉnh kích thước lại. Trong việc thực hiện ziplistResize sẽ gọi allocatorzipPrevLenByteDifftỷ số bóng đá hôm nay, nó có thể gây ra sao chép dữ liệu.nextdiffTrường. Ngoài ratỷ số bóng đá hôm nay, có thể cần điều chỉnh kích thước của ziplist - Cuối cùngkết quả bóng đá việt nam hôm nay, sắp xếp mục dữ liệu mới cần chèn, đặt tại vị trí p.
ziplistResizeHash và ziplistzrealloc, hoặc - Bây giờ khi đã có thêm không giantỷ số bóng đá hôm nay, bước tiếp theo là di chuyển tất cả các mục dữ liệu từ vị trí p và những phần còn lại về sau một bước sang bên phải, đồng thời chuẩn bị đặt một mục mới vào vị trí đã giải phóng. Điều này giúp sắp xếp dữ liệu theo đúng thứ tự mong muốn mà không làm mất bất kỳ thông tin nào.
<prevrawlen></prevrawlen>)kết quả bóng đá ngoại hạng anh, cũng hỗ trợ truy xuất riêng lẻ theo một field cụ thể (theo<zltail></zltail>trường. - Khi chúng ta thực hiện lần đầu tiên cho một key nào đó
của trên
Trong Rediskết quả bóng đá việt nam hôm nay, kiểu dữ liệu hash là lựa chọn khá lý tưởng để lưu trữ cấu trúc của một đối tượng. Mỗi thuộc tính của đối tượng có thể được ánh xạ trực tiếp vào các trường (fields) trong cấu trúc hash. Điều này giúp việc quản lý và truy xuất thông tin trở nên đơn giản và hiệu quả hơn. Với hash, bạn có thể dễ dàng thêm, sửa hoặc xóa từng phần tử riêng lẻ mà không cần phải thao tác trên toàn bộ đối tượng, mang lại sự linh hoạt và tối ưu hóa hiệu suất khi làm việc với dữ liệu phức tạp.
Chúng ta dễ dàng tìm thấy những bài viết kỹ thuật trên mạng nói rằng việc lưu trữ một đối tượng bằng cách sử dụng hash sẽ tiết kiệm bộ nhớ hơn so với string. Tuy nhiênkết quả bóng đá việt nam hôm nay, điều này không phải lúc nào cũng đúng, mà còn tùy thuộc vào cách đối tượng được lưu trữ. Nếu bạn lưu các thuộc tính của đối tượng vào nhiều key riêng lẻ (mỗi giá trị thuộc tính được lưu dưới dạng chuỗi), tất nhiên sẽ tiêu tốn nhiều bộ nhớ hơn. Nhưng nếu áp dụng một số phương pháp serialize, chẳng hạn như: - Sử dụng JSON để chuyển đổi đối tượng thành chuỗi, trong trường hợp này, việc lưu trữ sẽ gọn nhẹ hơn vì dữ liệu chỉ cần duy trì ở định dạng mã hóa duy nhất. - Lựa chọn các thuật toán compression mạnh mẽ, chẳng hạn như Gzip hoặc zlib, giúp giảm đáng kể kích thước của dữ liệu khi lưu trữ mà vẫn đảm bảo khả năng truy xuất nhanh chóng. - Ứng dụng các cấu trúc dữ liệu nhị phân, ví dụ như Protocol Buffers hoặc Avro, có thể tối ưu hóa việc lưu trữ và truyền tải dữ liệu một cách hiệu quả hơn so với việc lưu trữ từng chuỗi rời rạc. Tùy thuộc vào nhu cầu cụ thể của ứng dụng, bạn nên cân nhắc kỹ lưỡng trước khi lựa chọn phương án nào để tối ưu hóa tài nguyên hệ thống. Protocol Buffers nhưng Apache Thrift Khi bạn đầu tiên chuyển đối tượng thành mảng bytekết quả bóng đá ngoại hạng anh, sau đó lưu vào chuỗi của Redis, thì việc so sánh với kiểu hash về mặt tiết kiệm bộ nhớ chưa chắc đã có câu trả lời rõ ràng. Trong trường hợp sử dụng chuỗi (string), kích thước dữ liệu sẽ phụ thuộc vào độ dài của chuỗi được lưu trữ. Tuy nhiên, khi dùng hash, mỗi trường trong đối tượng sẽ được lưu dưới dạng một cặp key-value riêng biệt, điều này có thể làm giảm đáng kể kích thước nếu một số trường không cần thiết phải được lưu ở mọi thời điểm. Mặt khác, hash cũng có thể giúp tối ưu hóa hơn trong việc truy xuất từng phần dữ liệu mà không cần tải toàn bộ nội dung như khi sử dụng string. Vì vậy, sự lựa chọn giữa hai cách này thường phụ thuộc vào cấu trúc dữ liệu và nhu cầu cụ thể của ứng dụng bạn đang phát triển.
Bạn có thể thấy rằng so với việc serialize dữ liệu thành chuỗi rồi lưu trữtỷ số bóng đá hôm nay, hash vẫn có những lợi thế nhất định trong việc hỗ trợ các lệnh thao tác. Đặc biệt, hash cho phép bạn truy xuất hoặc cập nhật nhiều trường (fields) cùng một lúc mà không cần phải thực hiện từng bước riêng lẻ, điều này giúp tiết kiệm thời gian và tăng hiệu quả xử lý.
hmset
/
hmget
của đối tượng robj.
hset
/
hget
)。
Trên thực tếkết quả bóng đá việt nam hôm nay, khi kích thước dữ liệu tăng lên, cách thức triển khai cấu trúc dữ liệu bên dưới hash cũng sẽ thay đổi, và tất nhiên, hiệu quả lưu trữ cũng sẽ khác nhau. Khi số lượng trường (field) ít và các giá trị (value) tương đối nhỏ, hash thường được thực hiện bằng ziplist; còn khi số lượng trường tăng lên và các giá trị lớn hơn, hash có thể chuyển sang sử dụng dict để triển khai. Khi hash chuyển sang sử dụng dict ở phía dưới, hiệu suất lưu trữ của nó sẽ không thể so sánh với những phương pháp tuần tự hóa (serialization) khác. Điều này cho thấy sự linh hoạt và khả năng thích nghi của hash trong việc điều chỉnh cấu trúc dữ liệu theo yêu cầu cụ thể của từng tình huống.
Thực tếkết quả bóng đá ngoại hạng anh, ví dụ ziplist được đưa ra ở phần trước của bài viết này, được xây dựng bởi hai lệnh sau đây.
hset key field value
Khi thực hiện lệnhkết quả bóng đá việt nam hôm nay, Redis sẽ tạo ra một cấu trúc hash, và hash mới được tạo này về cơ bản sẽ sử dụng dạng ziplist làm nền tảng lưu trữ bên dưới. Ziplist là một phương thức tối ưu hóa hiệu suất cho phép lưu trữ các cặp key-value với không gian chiếm dụng ít hơn khi kích thước của dữ liệu không quá lớn. Điều này giúp tăng cường khả năng quản lý bộ nhớ trong các trường hợp dữ liệu vừa và nhỏ, đồng thời vẫn đảm bảo hiệu quả hoạt động của Redis.
robj
*
createHashObject
(
void
)
{
unsigned
char
*
zl
=
ziplistNew
();
robj
*
o
=
createObject
(
OBJ_HASH
,
zl
);
o
->
encoding
=
OBJ_ENCODING_ZIPLIST
;
return
o
;
}
Mỗi lần thực hiện
createHashObject
Hàm nàytỷ số bóng đá hôm nay, được định nghĩ c, có nhiệm vụ chính là tạo ra một cấu trúc hash mới. Khi phân tích, chúng ta nhận thấy rằng nó đã khởi tạo một đối tượng với các thuộc tính cần thiết để xây dựng nên cơ chế quản lý dữ liệu dạng bảng băm (hash table). Quy trình bắt đầu bằng việc cấp phát bộ nhớ và thiết lập các tham số nền tảng cho phép hệ thống lưu trữ và truy xuất thông tin một cách hiệu quả.
type = OBJ_HASH
tạo ra hai mục dữ liệu).
encoding = OBJ_ENCODING_ZIPLIST
Ý nghĩa của cấu hình này là khi một trong hai điều kiện sau đây được thỏa mãntỷ số bóng đá hôm nay, ziplist sẽ chuyển thành dict:
Hàm).
hset user:100 name tielei
hset user:100 age 20
Mỗi lần chèn hoặc sửa đổi gây ra realloc sẽ có khả năng lớn hơn gây ra sao chép bộ nhớkết quả bóng đá ngoại hạng anh, từ đó làm giảm hiệu suất.
hset
Bạn có thể chèn trường (field) và giá trị (value) được chỉ định vào trong danh sách liên kết (ziplist) dưới dạng hai mục dữ liệu riêng biệt mới (tức là mỗi lần thực hiện lệnh). Điều này giúp phân tách rõ ràng từng thành phầnkết quả bóng đá việt nam hôm nay, cho phép dễ dàng quản lý và truy xuất thông tin sau này một cách hiệu quả.
hset
Một khi xảy ra sao chép bộ nhớtỷ số bóng đá hôm nay, chi phí sao chép bộ nhớ cũng sẽ tăng lên, vì phải sao chép khối dữ liệu lớn hơn.
Khi dữ liệu được chèn vàokết quả bóng đá việt nam hôm nay, cấu trúc ziplist ở tầng dưới cùng có thể sẽ chuyển đổi thành dạng dict. Nhưng rốt cuộc thì cần chèn bao nhiêu dữ liệu thì mới xảy ra sự chuyển đổi này? Có rất nhiều yếu tố ảnh hưởng đến điều này, chẳng hạn như kích thước của các phần tử trong ziplist và cấu hình tối đa cho phép. Một khi kích thước hoặc số lượng phần tử vượt quá giới hạn cho phép, hệ thống sẽ tự động chuyển đổi để đảm bảo hiệu suất hoạt động tốt hơn.
Bạn còn nhớ hai cấu hình Redis được đề cập ở đầu bài không?
hash-max-ziplist-entries 512
hash-max-ziplist-value 64
Bài tiếp theo chúng tôi sẽ giới thiệu quicklisttỷ số bóng đá hôm nay, xin hãy đón chờ.
- Khi số lượng mục dữ liệu (cặp trường-giá trị) trong hash vượt quá 512tỷ số bóng đá hôm nay, cụ thể là khi số lượng mục trong danh sách liên kết kiểu ziplist vượt quá 1024 (hãy tham khảo t_hash.c), điều này có nghĩa là... Hoặc một cách sáng tạo hơn: Khi khối lượng dữ liệu trong cấu trúc hash ngày càng gia tăng và đạt đến mức hơn 512 mục, tức là danh sách liên kết ziplist chứa nhiều hơn 1024 phần tử (theo định nghĩa trong t_hash.c), thì... Tôi đã kiểm tra kỹ lưỡng và không còn bất kỳ ký tự nào ngoài tiếng Việt.
hashTypeSetMột khi xảy ra sao chép bộ nhớkết quả bóng đá ngoại hạng anh, chi phí sao chép bộ nhớ cũng sẽ tăng lên, vì phải sao chép khối dữ liệu lớn hơn. - Khi bất kỳ giá trị nào được chèn vào hash có độ dài vượt quá 64 ký tự (hãy tham khảo t_hash.c bên dưới)tỷ số bóng đá hôm nay,
hashTypeTryConversionMột khi xảy ra sao chép bộ nhớtỷ số bóng đá hôm nay, chi phí sao chép bộ nhớ cũng sẽ tăng lên, vì phải sao chép khối dữ liệu lớn hơn.
Thiết kế của Redis dạng hash như vậy là do khi ziplist trở nên quá lớnkết quả bóng đá ngoại hạng anh, nó có một số nhược điểm sau đây: Thứ nhất, hiệu suất truy xuất dữ liệu sẽ giảm đáng kể. Khi kích thước ziplist tăng lên, việc tìm kiếm hoặc thao tác với các phần tử trở nên chậm hơn vì cần phải duyệt qua nhiều phần tử hơn. Thứ hai, việc sử dụng bộ nhớ không còn tối ưu nữa. Khi ziplist mở rộng, các yếu tố cấu trúc phụ trợ cũng chiếm thêm không gian, làm gia tăng tiêu hao tài nguyên hệ thống. Thứ ba, khả năng duy trì tính ổn định bị ảnh hưởng. Một ziplist lớn hơn có nguy cơ gặp lỗi khi xử lý dữ liệu, dẫn đến rủi ro mất mát thông tin hoặc sự cố trong quá trình vận hành. Vì những lý do trên, Redis đã thiết kế một cơ chế chuyển đổi linh hoạt để tối ưu hóa hiệu suất và bảo vệ dữ liệu một cách tốt nhất.
- Bài tiếp theo chúng tôi sẽ giới thiệu quicklistkết quả bóng đá việt nam hôm nay, xin hãy đón chờ.
- Khi số lượng mục dữ liệu trong ziplist trở nên quá lớnkết quả bóng đá ngoại hạng anh, việc tìm kiếm một mục cụ thể sẽ trở nên rất kém hiệu quả, vì để tìm được mục cần tìm, ta phải duyệt qua toàn bộ các mục có Điều này dẫn đến thời gian xử lý tăng lên đáng kể và gây áp lực cho hệ thống khi phải làm việc với khối lượng dữ liệu khổng lồ.
Tóm lạikết quả bóng đá việt nam hôm nay, ziplist được thiết kế với mục đích để tất cả các phần tử dữ liệu nằm liền kề nhau, tạo thành một vùng nhớ liên tục. Kiến trúc này không thực sự hiệu quả trong việc thực hiện các thao tác sửa đổi. Khi có bất kỳ sự thay đổi nào xảy ra đối với dữ liệu, điều này có thể dẫn đến việc tái phân bổ bộ nhớ (realloc), từ đó gây ra việc sao chép bộ nhớ.
quicklist
Bài viết gốckết quả bóng đá việt nam hôm nay, vui lòng ghi rõ nguồn và bao gồm mã QR bên dưới! Nếu không, từ chối tái bản!
Liên kết bài viết này: /rc9othv0.html
Hãy theo dõi tài khoản Weibo cá nhân của tôi: Tìm kiếm tên tôi "Trương Thiết Lệ" trên Weibo.

Phân loại mục
Bài viết mới nhất
- Khái niệm, mức độ tự chủ và mức độ trừu tượng của AI Agent
- LangChain's OpenAI và ChatOpenAI, nên gọi cái nào?
- Phần tiếp theo của DSPy: Tìm hiểu thêm về o1, Lượng tính trong Thời gian Suy luận và Khả năng Lý luận Trong phần này, chúng ta sẽ đi sâu hơn vào thế giới của DSPy bằng cách khám phá những khái niệm quan trọng như ngôn ngữ lập trình o1, lượng tính toán trong giai đoạn suy luận và khả năng lý luận. Những yếu tố này không chỉ đóng vai trò then chốt trong việc nâng cao hiệu quả của hệ thống mà còn tạo ra một nền tảng vững chắc cho sự phát triển của trí tuệ nhân tạo. Ngôn ngữ lập trình o1 được thiết kế đặc biệt để tối ưu hóa quá trình xử lý thông tin và làm cho việc xây dựng các ứng dụng trở nên đơn giản hơn bao giờ hết. Với cách tiếp cận linh hoạt, o1 không chỉ giúp tiết kiệm thời gian mà còn đảm bảo độ chính xác cao trong việc thực thi các tác vụ phức tạp. Tiếp theo đó là khía cạnh lượng tính trong thời gian suy luận – đây là khái niệm mô tả số lượng tài nguyên máy tính cần thiết để thực hiện một thao tác nhất định. Hiểu rõ về vấn đề này giúp các nhà phát triển tối ưu hóa hệ thống để nó hoạt động hiệu quả hơn trong mọi tình huống. Cuối cùng nhưng không kém phần quan trọng, khả năng lý luận đóng vai trò như bộ não của hệ thống. Nó cho phép hệ thống không chỉ phản hồi trực tiếp từ dữ liệu mà còn có thể đưa ra các quyết định dựa trên logic và phân tích sâu rộng. Điều này mở ra cánh cửa cho những sáng tạo mới trong lĩnh vực AI, nơi trí thông minh không chỉ dừng lại ở việc làm theo lệnh mà còn tự đưa ra giải pháp cho những tình huống chưa từng gặp trước đây. Với tất cả những yếu tố trên, phần tiếp theo của DSPy sẽ mang đến cho bạn cái nhìn toàn diện về cách các công nghệ này kết hợp với nhau để tạo nên một hệ thống hoàn chỉnh và hiệu quả. Hãy cùng khám phá thêm!
- Nói chuyện sơ lược về DSPy và kỹ thuật tự động hóa gợi ý (phần giữa)
- Nói chuyện sơ lược về DSPy và kỹ thuật tự động hóa gợi ý (phần đầu)
- Kiến thức phổ thông: Giải mã nguyên lý xác suất đằng sau LLM
- Bắt đầu từ Vương Tiểu Bảo: ranh giới đạo đức và quan điểm thiện ác của người bình thường
- Xem xét lại thông tin qua GraphRAG
- Những thay đổi và bất biến trong sự thay đổi công nghệ: Làm thế nào để tạo ra token nhanh hơn?
- Thể trí doanh nghiệp, số hóa và phân công ngành nghề trong lĩnh vực