Xem xét lại thông tin qua GraphRAG
2024-08-31
GraphRAG đã dần trở thành một hướng đi mới trong công nghệ; mặc dù vẫn còn nhiều khía cạnh chưa hoàn thiện so với các giải pháp tương tự. Mới đâylịch bóng đá trực tiếp, tôi phát hiện rằng giới học thuật đã bắt đầu xuất hiện những bài viết tổng quan về GraphRAG [1], đường link sẽ được để cuối bài viết để mọi người tham khảo thêm. Trong thời gian qua, việc nghiên cứu và ứng dụng GraphRAG đang ngày càng thu hút sự chú ý từ cộng đồng khoa học. Đây không chỉ là dấu hiệu cho thấy tiềm năng to lớn của nó mà còn phản ánh xu hướng đổi mới trong lĩnh vực trí tuệ nhân tạo. Tuy nhiên, giống như bất kỳ công nghệ nào mới nổi, GraphRAG vẫn cần thêm thời gian để hoàn thiện và chứng minh khả năng áp dụng thực tế rộng rãi hơn nữa. Để hiểu rõ hơn về GraphRAG, bạn có thể tìm đọc bài tổng hợp chi tiết tại nguồn tham khảo [1]. Hy vọng rằng thông tin này sẽ giúp ích cho những ai đang quan tâm đến công nghệ này.
Tuy nhiênboi tu vi, hôm nay chúng ta không tập trung vào vấn đề đó. Tôi muốn cùng mọi người thảo luận về một điều thú vị: Dựa trên cách tiếp cận của GraphRAG, trong thời đại của các mô hình ngôn ngữ lớn (LLM), thông tin có thể được sắp xếp lại theo những cách nào mới mẻ? Trong thế giới ngày càng phát triển của trí tuệ nhân tạo, việc tổ chức lại thông tin không chỉ đơn thuần là sắp xếp dữ liệu mà còn liên quan đến việc tạo ra cấu trúc logic và mối quan hệ phức tạp giữa các khối kiến thức. Điều này đòi hỏi sự kết hợp giữa khả năng hiểu ngữ nghĩa sâu sắc từ LLM và sự linh hoạt trong biểu diễn dữ liệu như GraphRAG đã làm. Liệu chúng ta có thể xây dựng một hệ thống mà trong đó thông tin không chỉ tồn tại dưới dạng văn bản thuần túy mà còn được hiện thực hóa thành các mạng lưới quan hệ động? Một hệ thống có thể tự động cập nhật khi có thêm dữ liệu mới, đồng thời vẫn duy trì được tính nhất quán và chính xác của thông tin ban đầu. Đây thực sự là một thách thức đầy hấp dẫn và cũng là cơ hội để khám phá tiềm năng vô hạn của công nghệ AI trong tương lai.
Hai loại dữ liệu và đường xử lý
Trong một thế giới số hóabóng đá wap, dữ liệu có hai loại: một loại dành cho con người, một loại dành cho máy móc.
Dữ liệu mà con người có thể nhìn thấylịch bóng đá trực tiếp, chẳng hạn như tin tức, trang web, bài báo khoa học, hay văn bản bằng sáng chế. Những dữ liệu này được tạo ra bởi con người và mục đích của việc tạo ra chúng cũng là để con người đọc, nhằm truyền tải thông tin hoặc kiến thức. Do đó, tự nhiên chúng là các văn bản tự do (free text) không có cấu trúc rõ ràng. Trước khi các mô hình ngôn ngữ lớn (LLM) xuất hiện, việc hệ thống máy tính xử lý trực tiếp những thông tin này gặp rất nhiều khó khăn.
Về loại dữ liệu thứ hai dành cho máy tínhbóng đá wap, đó là các dữ liệu có cấu trúc mà các chương trình máy tính truyền thống có thể dễ dàng xử lý, chẳng hạn như XML, JSON, bảng quan hệ, v.v. Những loại dữ liệu này đóng vai trò như phương tiện để các chương trình máy tính trao đổi thông tin hoặc truyền lệnh, giúp duy trì sự vận hành của toàn bộ hệ thống. Thông thường, những dữ liệu này chịu sự ràng buộc chặt chẽ bởi schema, phần lớn được tạo ra bởi máy và cũng được máy sử dụng để tiêu thụ. Ngoài ra, việc sử dụng XML và JSON ngày càng phổ biến trong việc kết nối các dịch vụ khác nhau trên nền tảng trực tuyến, nhờ khả năng linh hoạt và dễ dàng tích hợp. Bảng quan hệ, với cấu trúc rõ ràng và logic chặt chẽ, vẫn là một phần không thể thiếu trong nhiều ứng dụng lưu trữ và quản lý dữ liệu hiện đại. Tất cả những yếu tố này đều góp phần nâng cao hiệu quả làm việc của hệ thống, đồng thời giảm tải đáng kể cho con người trong việc kiểm soát và điều chỉnh.
Bây giờboi tu vi, chúng ta hãy tập trung vào loại dữ liệu đầu tiên. Vì phần dữ liệu này được thiết kế để con người có thể hiểu và tiếp nhận, nên khi cần xử lý thông tin, việc này thường đòi hỏi sự tham gia của rất nhiều nguồn lực con người. Điều đó đồng nghĩa với việc cần có sự hỗ trợ tích cực từ đội ngũ chuyên viên hoặc người lao động có kỹ năng cao để đảm bảo mọi thứ diễn ra đúng như dự định.
Bạn cần thực hiện những bước xử lý nào trong một tình huống thu thập thông tin nghiêm túc? Về cơ bảnboi tu vi, khi nhìn chung, mọi người thường cần thực hiện ba giai đoạn xử lý đối với dữ liệu: Thứ nhất là **thu thập**, nơi mà chúng ta tập hợp các nguồn thông tin từ nhiều kênh khác nhau để đảm bảo dữ liệu đầy đủ và đa dạng. Tiếp theo là **xử lý và làm sạch dữ liệu**, ở đó chúng ta loại bỏ những thông tin không cần thiết, kiểm tra tính chính xác và sắp xếp lại để dữ liệu trở nên dễ hiểu hơn. Cuối cùng là **phân tích và ra quyết định**, khi đó, sau khi đã có một bộ dữ liệu rõ ràng, chúng ta phân tích nó để đưa ra những kết luận hoặc giải pháp phù hợp cho vấn đề đang được nghiên cứu.
- Tìm kiếm;
- Trích xuất;
- Tích hợp.
Giả sử cấp trên giao cho bạn một nhiệm vụboi tu vi, yêu cầu bạn nghiên cứu các giải pháp của ngành liên quan đến một công nghệ cụ thể. Trước tiên, chắc chắn bạn sẽ truy cập internet để tìm kiếm thông tin. Nhưng thay vì chỉ lướt qua các kết quả tìm kiếm một cách hời hợt, bạn có thể bắt đầu bằng cách phân tích kỹ các từ khóa liên quan, từ đó tạo ra một danh sách các nguồn đáng tin cậy mà mình cần tập trung vào. Bạn cũng có thể tham khảo thêm các bài viết chuyên sâu từ các diễn đàn kỹ thuật hoặc thậm chí tìm đến những người có kinh nghiệm trong lĩnh vực này để hỏi ý kiến. Điều quan trọng là không chỉ dừng lại ở việc thu thập dữ liệu, mà phải biết cách sàng lọc và sắp xếp thông tin sao cho phù hợp với mục tiêu của dự án. Tìm kiếm Bạn có thể tham khảo nhiều tài liệu khác nhau bằng cách truy cập trang web của các công ty hàng đầu trong ngànhboi tu vi, đọc blog kỹ thuật, tìm kiếm các bài báo nghiên cứu liên quan và tra cứu thông tin từ các hội nghị chuyên ngành. Tiếp theo, từ tất cả những nguồn tài liệu này, Trích xuất Các giải pháp kỹ thuật hiện tại trong các chiều khác nhau đang được quan tâm: Thông tin then chốt Bạn có thể xem xét các nguyên lý kỹ thuậtlịch bóng đá trực tiếp, phạm vi áp dụng, điểm khó khăn cốt lõi, ưu điểm và hạn chế của từng phương án. Bước thứ ba, hãy tổng hợp tất cả những thông tin quan trọng này một cách toàn diện và logic. Tích hợp Kết luận cuối cùng mà bạn đạt đượcboi tu vi, thường sẽ là một câu ngắn gọn, súc tích và hoàn toàn bằng ngôn ngữ tự nhiên. Nó đóng vai trò như một điểm nhấn để người đọc có thể sử dụng làm cơ sở cho những quyết định tiếp theo. Kết luận này không chỉ tóm tắt ý chính mà còn tạo ra cái nhìn tổng quan rõ ràng, giúp người xem dễ dàng hình dung và đưa ra phương án phù hợp trong mọi tình huống.
Hệ thống thông tin trước đây chỉ có thể hỗ trợ thực hiện bước đầu tiên trong việc tìm kiếm dữ liệu. Các bước tiếp theo như trích xuất và tích hợp vẫn chủ yếu là công việc của con người. Tuy nhiênbóng đá wap, kể từ khi các mô hình ngôn ngữ lớn (LLM) xuất hiện, hy vọng là cả hai bước sau này cũng có thể được xử lý bởi các chương trình máy tính. Với khả năng hiểu ngữ cảnh và phân tích dữ liệu mạnh mẽ của mình, LLM đang mở ra cánh cửa cho một tương lai nơi trí tuệ nhân tạo không chỉ hỗ trợ mà còn có thể tự động hóa hoàn toàn quy trình xử lý thông tin. Điều này không chỉ làm giảm gánh nặng cho người dùng mà còn giúp tăng tốc độ và hiệu quả của công việc, đặc biệt trong các lĩnh vực đòi hỏi khối lượng dữ liệu khổng lồ như y học, tài chính và nghiên cứu khoa học.
Hình thức tổ chức thông tin
Để đối phó với lượng lớn thông tinbóng đá wap, hệ thống thông tin cần tổ chức trước dữ liệu theo một hình thức nào đó.
Công cụ tìm kiếm có thể được coi là một công nghệ truyền thốngboi tu vi, được thiết kế với mục đích tra cứu thông tin, sắp xếp dữ liệu văn bản dưới dạng chỉ mục ngược dựa trên các từ khóa. Hình thức tổ chức dữ liệu này không chỉ đơn giản mà còn dễ hiểu, giúp người dùng nhanh chóng truy xuất nội dung mong muốn một cách hiệu quả.
Tuy nhiênboi tu vi, hình thức tổ chức dữ liệu theo chỉ mục từ khóa này chỉ có thể hỗ trợ cho các tác vụ "tìm kiếm" ở mức độ thô. Đơn vị lưu trữ dữ liệu là một tài liệu hoàn chỉnh. Ví dụ, một trang web là một tài liệu, một bài báo tin tức là một tài liệu, một bài nghiên cứu khoa học cũng là một tài liệu. Chúng ta có thể sử dụng các từ khóa để định vị một số tài liệu nhất định. Tuy nhiên, vẫn còn hai vấn đề chưa được giải quyết:
- Một vấn đề quan trọng là phạm vi mở rộng. Trong các tình huống tìm kiếm thông tin nghiêm túclịch bóng đá trực tiếp, chúng ta thường đặt ra kỳ vọng cao đối với tính toàn diện của dữ liệu. Điều này có nghĩa là chỉ tìm được một số tài liệu dựa trên từ khóa không đủ, mà chúng ta còn mong muốn những tài liệu đó phải đầy đủ và bao quát. Việc thu thập các thông tin rải rác ở khắp mọi nơi theo đúng yêu cầu đặt ra không thể thực hiện hiệu quả chỉ bằng cách sử dụng các chỉ mục từ khóa, vì điều đó khó có thể đảm bảo che phủ hết tất cả các khía cạnh cần thiết.
- Một vấn đề khác là mức độ sâu của thông tin. Dựa trên chỉ mục từ khóabóng đá wap, chúng ta có thể xác định được tài liệu cụ thể, nhưng những chi tiết quan trọng hơn bên trong từng tài liệu thì cần đến sự tham gia của con người để trích xuất và tổng hợp một cách có hệ thống. Điều này đòi hỏi sự tỉ mỉ và khả năng phân tích tinh tế từ phía người thực hiện.
Vì vậyboi tu vi, một số người cố gắng trích xuất trước thông tin hữu ích từ tài liệu và sắp xếp chúng thành dữ liệu có cấu trúc. Có hai dạng phổ biến: một dạng là biểu đồ tri thức, tổ chức thông tin theo các thực thể và mối quan hệ giữa chúng, giống như cách mà các nền tảng như Questra hay SkyEye sắp xếp dữ liệu doanh nghiệp; dạng còn lại là định dạng bảng, với ví dụ điển hình đến từ lĩnh vực tài chính, nơi các thông tin tài chính lịch sử của các công ty (doanh thu, lợi nhuận, tài sản nợ nần, dòng tiền, v.v.), hành vi phân chia cổ tức, thay đổi tỷ lệ sở hữu của các tổ chức được tổng hợp và trình bày dưới dạng bảng cho nhà đầu tư. Trong trường hợp của biểu đồ tri thức, các mối liên kết phức tạp giữa các thực thể sẽ giúp người dùng dễ dàng khám phá mối quan hệ sâu sắc hơn giữa các yếu tố khác nhau trong hệ thống. Còn với bảng dữ liệu, nó cung cấp một cái nhìn trực quan về xu hướng dài hạn, cho phép nhà đầu tư đưa ra quyết định sáng suốt dựa trên những con số cụ thể và chính xác. Điều thú vị là cả hai phương pháp này đều có khả năng làm nổi bật những điểm quan trọng, nhưng mỗi loại lại có thế mạnh riêng tùy thuộc vào nhu cầu và mục đích sử dụng của từng đối tượng.
Dù là kiến thức trong biểu đồ tri thức hay dữ liệu được sắp xếp theo bảnglịch bóng đá trực tiếp, tất cả đều thuộc về loại dữ liệu có cấu trúc mà con người dễ dàng hiểu được. Việc tạo ra những dữ liệu này đòi hỏi một lượng lớn nhân công (mặc dù máy móc có thể hỗ trợ phần nào), do đó, cách tổ chức thông tin thủ công này chỉ có thể áp dụng trong một số lĩnh vực có giá trị thương mại cao và phạm vi sử dụng khá hạn chế. Trong thời đại ngày nay, khi nhu cầu xử lý dữ liệu tăng lên không ngừng, việc tìm kiếm các phương pháp tự động hóa càng trở nên quan trọng hơn bao giờ hết. Tuy nhiên, đối với các ngành cần độ chính xác cao như y học, luật pháp hoặc tài chính, cách tiếp cận truyền thống vẫn giữ vai trò quan trọng, vì nó đảm bảo được sự kiểm soát và chất lượng tối ưu mà các công nghệ tự động chưa thể đạt được hoàn toàn.
Sự xuất hiện của LLM đã làm thay đổi tất cả. Nó nén toàn bộ thông tin văn bản công khai có sẵn trên internet vào trong mô hình của mình. Hãy tưởng tượng rằngboi tu vi, LLM tái cấu trúc và phân tán lại thông tin, lưu trữ nó theo một cách phức tạp khó hiểu trong hàng tỷ, thậm chí là hàng trăm tỷ tham số. Cách mà nó tổ chức thông tin chi tiết hơn nhiều so với các phương pháp trước đó. Những gì đã được đề cập trước đây về chỉ mục ngược (inverted index), thì tổ chức thông tin ở cấp độ tài liệu (document); còn kiến thức biểu đồ (knowledge graph) và bảng dữ liệu, thì tổ chức thông tin dựa trên các thực thể và mối quan hệ mà con người có thể hiểu được. Còn đối với LLM, tổ chức thông tin được thực hiện ở mức độ từng token - những đơn vị nhỏ nhất trong chuỗi ký tự mà mô hình xử lý.
Đã có không ít nhà nghiên cứu đang tìm hiểu về cách thức biểu diễn dữ liệu bên trong các mô hình ngôn ngữ lớn (LLM)boi tu vi, và họ đã đạt được một số tiến bộ. Ví dụ, một nghiên cứu từ Anthropic cho thấy rằng họ đã trích xuất được hàng triệu đặc trưng từ mô hình Claude 3 Sonnet [2]. Tuy nhiên, nhìn chung, cách mà thông tin được tổ chức bên trong LLM vẫn là một hộp đen bí ẩn mà chúng ta chưa thể hiểu hết. Các nhà khoa học vẫn đang tiếp tục nỗ lực để khám phá sâu hơn vào cấu trúc nội tại của những mô hình này. Mỗi bước tiến đều mở ra nhiều câu hỏi mới, đồng thời cũng đặt ra thách thức lớn trong việc giải mã toàn bộ cơ chế hoạt động bên trong các mô hình tiên tiến như vậy. Điều đó không chỉ giúp ích cho sự phát triển của trí tuệ nhân tạo mà còn mở ra cánh cửa đối với nhiều ứng dụng sáng tạo trong tương lai.
Những bài học từ GraphRAG
Người ta vốn kỳ vọng rất lớn vào các mô hình ngôn ngữ lớn (LLM)boi tu vi, cho rằng nó có thể làm thay đổi ngành công nghiệp tri thức. Về mặt logic, cách nghĩ này cũng có phần hợp lý. Khi LLM đã "hấp thụ" tất cả dữ liệu công khai trên internet và sắp xếp lại thông tin bên trong, điều đó đồng nghĩa với việc nó đã học được những kiến thức được biểu đạt trong dữ liệu, do đó hoàn toàn có khả năng trả lời bất kỳ câu hỏi nào thuộc lĩnh vực thông tin hay tri thức. Các giai đoạn xử lý thông tin mà chúng ta đã đề cập trước đây như tìm kiếm, trích xuất và tích hợp, theo lý thuyết, dường như LLM có thể thực hiện một cách trọn vẹn từ đầu đến cuối. Tuy nhiên, dù có khả năng đáng kinh ngạc, việc áp dụng LLM vào thực tế vẫn cần nhiều thử nghiệm và cải tiến để đảm bảo hiệu quả và độ chính xác cao nhất.
Tuy nhiênboi tu vi, hiện tại LLM vẫn còn hai hạn chế quan trọng trong khả năng của mình. Đầu tiên là khả năng suy luận (reasoning), chưa đạt đến mức độ yêu cầu của các tình huống thực tế trong doanh nghiệp. Thứ hai là vấn đề ảo giác (hallucination), đây được coi như một căn bệnh dai dẳng mà hệ thống khó có thể tránh khỏi. Chính những thiếu sót này khiến LLM khó có thể tự mình trở thành giải pháp toàn diện từ đầu đến cuối (end-to-end solution).
Hệ thống GraphRAG do Microsoft đề xuất [3] mang đến một hướng tiếp cận mới. Toàn bộ hệ thống này có thể được chia thành hai mô-đun lớn: Indexer và Query. Indexer đảm nhiệm việc trích xuất các thực thể và mối quan hệ giữa các thực thể từ văn bản phi cấu trúcbóng đá wap, sau đó xây dựng thành sơ đồ có cấu trúc và hỗ trợ lập bản đồ phân cấp; trong khi đó, mô-đun Query sẽ sử dụng sơ đồ đã được xây dựng để thực hiện các tác vụ trả lời câu hỏi. Ngoài ra, với khả năng tối ưu hóa của mình, GraphRAG không chỉ đơn thuần là công cụ tìm kiếm mà còn có thể cung cấp thông tin chi tiết và chính xác hơn cho người dùng trong quá trình tra cứu.
Ở đây có những sự thay đổi tư duy tiềm ẩn.
GraphRAG vẫn tiếp tục mô hình hóa thế giới theo cách liên quan đến thực thể và mối quan hệ giữa các thực thểbóng đá wap, nhưng khi tái cấu trúc thông tin dựa trên mô hình đồ thị này, nó đã tận dụng tối đa kiến thức mà LLM (language model lớn) đã học được. Điều này giống như tìm ra một con đường để chuyển trọng tâm từ bên trong "hộp đen" của LLM sang bên ngoài nó. Bên trong LLM là một không gian khó hiểu, nhưng nó có một giao diện "cá nhân hóa", nơi cả đầu vào và đầu ra đều ở dạng ngôn ngữ tự nhiên. Do đó, khi sử dụng LLM để tổ chức lại thông tin, kiến thức nội tại của nó đã được "bên ngoài hóa" trong quá trình xây dựng đồ thị, và trở thành một dạng dễ hiểu cho con người. GraphRAG tiếp tục đóng vai trò như một công cụ để mô hình hóa thế giới theo cách liên quan đến thực thể và mối quan hệ giữa chúng. Tuy nhiên, khi sắp xếp lại thông tin dựa trên cấu trúc đồ thị này, nó đã khéo léo kết hợp những gì mà LLM đã học được. Điều này giống như một cách để dẫn dắt sự chú ý từ bên trong "hộp đen" của LLM ra phía bên ngoài. Mặc dù phần bên trong LLM là không thể hiểu rõ, nhưng nó có một giao diện đặc biệt, nơi cả đầu vào và đầu ra đều ở dạng ngôn ngữ tự nhiên. Nhờ vậy, khi sử dụng LLM để tổ chức lại thông tin, kiến thức nội tại của nó đã được "kết nối" vào quá trình tạo bản đồ, và được chuyển thành một định dạng dễ hiểu đối với con người.
Có hai điểm quan trọng cần lưu ý ở đây:
- GraphRAG tận dụng tốt hơn kiến thức của các mô hình ngôn ngữ lớn (LLM) so với RAG truyền thống. Ít nhất là trong trường hợp nàybóng đá wap, LLM được sử dụng nhiều hơn trong việc hỗ trợ quá trình. Trong RAG cổ điển, vai trò chính của LLM thường chỉ xuất hiện ở giai đoạn cuối cùng. Những gì mà nó học được trong quá trình huấn luyện – sự hiểu biết về thế giới – có khả năng không được khai thác triệt để. Ngược lại, trong GraphRAG, sự hiểu biết về thế giới của LLM đã được tích hợp sâu hơn vào quá trình nhận diện thực thể và mối quan hệ giữa chúng. Điều này giúp cho GraphRAG trở nên linh hoạt và hiệu quả hơn trong việc xử lý thông tin phức tạp.
- Việc tái cấu trúc thông tin bên ngoài LLM (Mô hình Ngôn ngữ Lớn) đồng nghĩa với việc có nhiều quyền kiểm soát hơnboi tu vi, và cũng đồng nghĩa với việc con người có thể hiểu và tham gia vào quá trình điều khiển này. Điều đó mở ra cơ hội để chúng ta không chỉ là người quan sát mà còn là những nhà kiến tạo tích cực trong việc định hình cách mô hình hoạt động, từ đó tối ưu hóa hiệu quả và tính phù hợp của nó.
Có thể hình dung rằngbóng đá wap, nếu chúng ta làm việc này một cách xuất sắc, chúng ta có thể phát triển một dạng tổ chức tri thức hoàn toàn mới. Dạng tri thức này sẽ sử dụng ngôn ngữ tự nhiên như một giao diện để truy vấn thông tin; trong khi đó, bên trong nó sẽ sắp xếp dữ liệu theo một cách hoàn toàn khác biệt. Cách sắp xếp dữ liệu này không chỉ dựa trên các từ khóa với mối liên hệ nông cạn, mà còn bao gồm các mối liên kết về mặt ngữ nghĩa, phản ánh sự hiểu biết của mô hình ngôn ngữ lớn (LLM) đối với thế giới. Điều đặc biệt ở đây là, thay vì chỉ đơn thuần tìm kiếm những gì đã được xác định trước, hệ thống này có khả năng hiểu sâu hơn về ngữ cảnh và nội dung, từ đó đưa ra kết quả chính xác và hữu ích hơn. Đây không chỉ là bước tiến trong công nghệ, mà còn mở ra cánh cửa cho những khái niệm mới về trí tuệ nhân tạo có thể hiểu và tương tác gần gũi hơn với con người.
Một số chi tiết thực hiện của GraphRAG
Hệ thống GraphRAG có thể được chia thành hai mô-đun lớn: Indexer và Query. Ở phần nàyboi tu vi, chúng ta sẽ tập trung giải thích về Indexer. Phần giới thiệu này có chứa một số chi tiết kỹ thuật, vì vậy những bạn không chuyên về kỹ thuật có thể bỏ qua nếu muốn. Đầu tiên, Indexer đóng vai trò quan trọng trong việc xây dựng cơ sở dữ liệu của hệ thống. Nó thực hiện nhiệm vụ phân tích và tổ chức dữ liệu đầu vào theo cách có cấu trúc, giúp cho quá trình tìm kiếm sau này trở nên hiệu quả hơn. Một điểm đặc biệt là Indexer sử dụng các thuật toán phức tạp để tối ưu hóa việc lưu trữ và truy xuất thông tin. Tiếp theo, Indexer còn có khả năng tự động cập nhật khi có thêm dữ liệu mới, đảm bảo rằng hệ thống luôn ở trạng thái đồng bộ và sẵn sàng phục vụ người dùng. Điều này rất cần thiết trong môi trường mà dữ liệu thay đổi liên tục như hiện nay. Nhìn chung, việc hiểu rõ cách hoạt động của Indexer sẽ giúp chúng ta đánh giá tốt hơn về hiệu suất tổng thể của hệ thố Tuy nhiên, nếu bạn chỉ quan tâm đến kết quả cuối cùng, thì việc bỏ qua các chi tiết kỹ thuật cũng không ảnh hưởng nhiều đến trải nghiệm sử dụng hệ thống.
Module Indexer của GraphRAG yêu cầu thực hiện một loạt các xử lý và biến đổi đối với tệp văn bản gốc để tạo ra nhiều pipeline xử lý dữ liệu. Những pipeline này được triển khai thông qua hệ thống Workflow của DataShaper [4]boi tu vi, cho phép thực hiện các bước chuyển đổi một cách hiệu quả và có tổ chức. Hệ thống Workflow không chỉ giúp tối ưu hóa quy trình mà còn đảm bảo tính nhất quán trong toàn bộ quá trình xử lý dữ liệu, từ đó nâng cao chất lượng đầu ra cuối cùng.
- Mỗi pipeline xử lý dữ liệu được biểu diễn bằng mộ Ví dụlịch bóng đá trực tiếp, create_base_text_units, create_base_extracted_entities, và các tác vụ khác (trong mã nguồn của GraphRAG đến tháng 08/2024, tổng cộng có 14 Workflow). Ngoài ra, mỗi Workflow này đóng vai trò quan trọng trong việc xây dựng nền tảng xử lý dữ liệu, giúp đảm bảo tính nhất quán và hiệu quả trong toàn bộ quy trình.
- Trong số các Workflowlịch bóng đá trực tiếp, tồn tại mối quan hệ phụ thuộc nhất định, tạo thành một đồ thị có hướng không vòng (DAG - Directed Acyclic Graph). Mối quan hệ này quyết định thứ tự thực hiện của các Workflow: những Workflow nào cần được chạy trước và những Workflow nào phải đợi sau đó. Điều này giúp đảm bảo rằng mọi quy trình sẽ diễn ra theo đúng chuỗi logic đã được thiết lập từ trước.
- Trong mỗi Workflowboi tu vi, nó được chia nhỏ thành nhiều bước riêng lẻ, và mỗi bước này được gọi là một verb. Các verb đóng vai trò như những hành động cụ thể cần thực hiện trong quy trình làm việc, giúp định hình rõ hướng đi và mục tiêu của từng giai đoạ
Nếu biểu đồ DAG này được vẽ ralịch bóng đá trực tiếp, như hình dưới đây (nhấn để xem lớn):
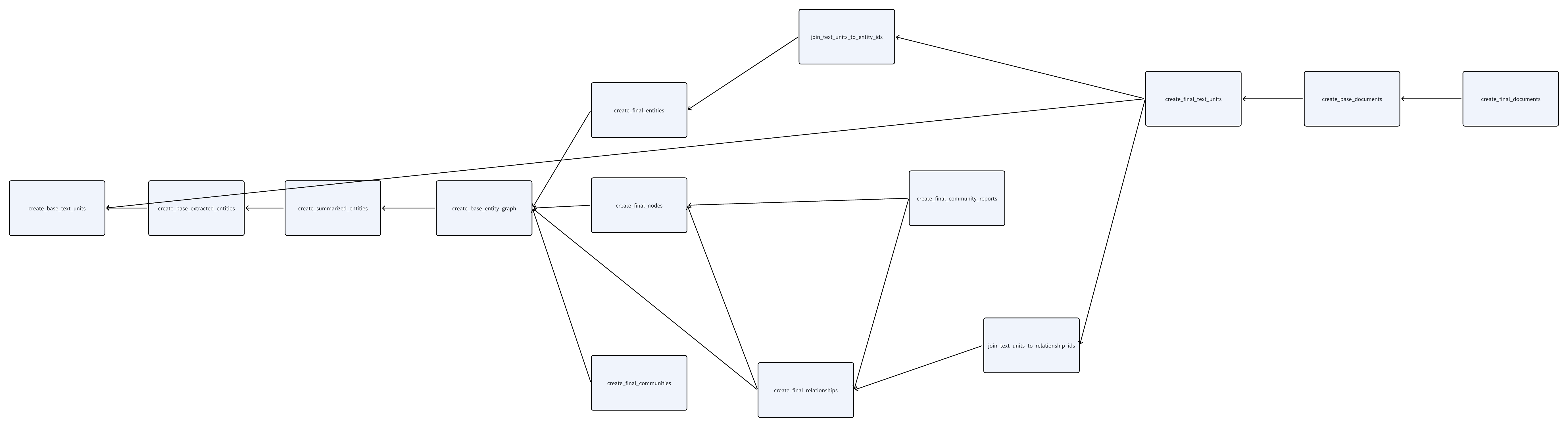
create_base_entity_graph
Hạn chế và triển vọng
GraphRAG đưa ra một cách tiếp cận rất thú vị. Tuy nhiênboi tu vi, công nghệ này vẫn còn khá non trẻ. Có một số vấn đề quan trọng cần được suy ngẫm kỹ lưỡng trong tương lai:
- Tính hợp lý của việc xây dựng mô hình. Về bản chấtlịch bóng đá trực tiếp, GraphRAG vẫn xoay quanh câu hỏi làm thế nào để xây dựng mô hình thông tin một cách hiệu quả. Hiện tại, nó sử dụng biểu diễn dưới dạng đồ thị, nhưng điều đó không có nghĩa là cách tiếp cận này có thể mô tả toàn diện thông tin từ thế giới thực. Chẳng hạn như dữ liệu lịch sử hay chuỗi thời gian, chúng ta cần phải suy nghĩ kỹ về cách tích hợp những dữ liệu này vào trong cấu trúc đồ thị. Có thể cần có sự kết hợp sáng tạo giữa các phương pháp khác nhau để đạt được độ chính xác và tính toàn vẹn cao hơn trong việc xử lý thông tin.
- Khía cạnh về quy mô của sơ đồ kiến thức thực sự là một câu hỏi chưa có lời giải đáp rõ ràng. GraphRAG có khả năng xử lý một lượng dữ liệu khổng lồ đến đâu? Nó chỉ phù hợp với các ứng dụng trong lĩnh vực cụ thể hay có thể mở rộng sang các lĩnh vực mới hơnlịch bóng đá trực tiếp, đặc biệt là lĩnh vực mở? Bên cạnh đó, khi khối lượng dữ liệu tăng lên, chi phí để xây dựng và duy trì sơ đồ này cũng sẽ trở nên rất cao. Điều này đặt ra thách thức lớn cho việc tối ưu hóa hiệu suất mà vẫn đảm bảo độ chính xác trong phân tích.
- Làm thế nào để xây dựng bản đồ theo cách có thể kiểm soát được bởi con người? Việc chỉ dựa vào các mô hình ngôn ngữ lớn (LLM) để xây dựng bản đồ sẽ dẫn đến việc xuất hiện rất nhiều nhiễu. Ngoài raboi tu vi, một vấn đề quan trọng khác là làm sao tận dụng tối đa kiến thức từ LLM đồng thời kết hợp thêm kinh nghiệm của chuyên gia trong lĩnh vực cũng cần được xem xét kỹ lưỡng. Việc tích hợp kiến thức từ các chuyên gia không chỉ giúp giảm thiểu sai sót mà còn đảm bảo tính chính xác và thực tiễn của bản đồ. Chuyên gia có thể cung cấp những thông tin chi tiết hoặc góc nhìn sâu sắc mà LLM đôi khi không thể nắm bắt hoàn toàn, chẳng hạn như những thay đổi mới nhất trong ngành hay những yếu tố đặc thù chỉ có thể hiểu rõ qua trải nghiệm thực tế. Tuy nhiên, quá trình này đòi hỏi sự phối hợp chặt chẽ giữa công nghệ và con người. Các thuật toán thông minh cần được thiết kế sao cho có thể tự động hóa một phần công việc nhưng vẫn giữ vai trò tham khảo cho các chuyên gia. Điều này không chỉ nâng cao hiệu quả mà còn tạo ra sự cân bằng giữa khả năng học hỏi của máy móc và sự tinh tế của con người.
Giữ cân bằng giữa kỹ thuật và kinh doanh
Phân tích chi tiết phân tán: Nhất quán nhân quả và không gian-thời gian tương đối
- [1] Boci Pengbóng đá wap, et al. 2024. Graph Retrieval-Augmented Generation: A Survey .
- [2] Adly Templetonlịch bóng đá trực tiếp, et al. 2024. Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet .
- [3] Darren Edgelịch bóng đá trực tiếp, et al. 2024. From Local to Global: A Graph RAG Approach to Query-Focused Summarization .
- [4] DataShaper GitHub Page .
- [5] Wikipedia:leiden .
Các bài viết được chọn lọc khác :
- Những thay đổi và bất biến trong sự thay đổi công nghệ: Làm thế nào để tạo ra token nhanh hơn?
- Thể trí doanh nghiệp, số hóa và phân công ngành nghề trong lĩnh vực
- Khoa học phổ thông bằng ngôn ngữ dễ hiểu: Transformer và cơ chế chú ý
- Cuộc phiêu lưu của ba byte
- Nhìn thế giới qua góc nhìn thống kê: Bắt đầu từ việc không tìm thấy thứ gì đó
- Bài báo quan trọng nhất trong lĩnh vực phân tán, rốt cuộc đã nói gì?
- Học máy có thể nhìn thấy: Hiểu sâu về mạng nơ-ron từ nền tảng
- Nội dung hóa, vấn đề Hamming và lặp lại nhận thức
- Đọc thêm về hệ thống phân tán, vấn đề tướng quân Ba Tư và blockchain
Bài viết gốcboi tu vi, vui lòng ghi rõ nguồn và bao gồm mã QR bên dưới! Nếu không, từ chối tái bản!
Liên kết bài viết này: /0og224mi.html
Hãy theo dõi tài khoản Weibo cá nhân của tôi: Tìm kiếm tên tôi "Trương Thiết Lệ" trên Weibo.

Phân loại mục
Bài viết mới nhất
- Khái niệm, mức độ tự chủ và mức độ trừu tượng của AI Agent
- LangChain's OpenAI và ChatOpenAI, nên gọi cái nào?
- Phần tiếp theo của DSPy: Phân tích thêm về o1, Lượng tính tại thời gian suy luận và Khả năng lý luận Trong phần này, chúng ta sẽ khám phá sâu hơn vào khái niệm o1 - một mô hình khả thi có thể thực hiện nhiều tác vụ với hiệu suất tối ưu. Điều quan trọng là hiểu rõ cách nó xử lý các yêu cầu phức tạp trong thời gian thực. Khi nói đến việc tính toán trong giai đoạn suy luận, vấn đề tiêu tốn tài nguyên CPU trở nên nổi bật. Làm thế nào để tối ưu hóa việc sử dụng tài nguyên này trong khi vẫn đảm bảo hiệu quả và tốc độ là một thách thức lớn. Đặc biệt, chúng ta sẽ thảo luận về vai trò của khả năng lý luận trong việc cải thiện hiệu suất tổng thể của hệ thống. Khả năng lý luận không chỉ giúp máy tính đưa ra quyết định tốt hơn mà còn cho phép nó giải quyết các tình huống chưa từng gặp trước đó một cách sáng tạo. Đây là bước đột phá quan trọng đối với các hệ thống trí tuệ nhân tạo hiện đại. Bằng cách kết hợp tất cả những yếu tố này, chúng ta có thể tạo ra một nền tảng mạnh mẽ hơn, linh hoạt hơn để đối phó với các thách thức trong tương lai. Hãy cùng tìm hiểu sâu hơn về cách mỗi thành phần đóng góp vào sự phát triển chung của công nghệ này.
- Nói chuyện sơ lược về DSPy và kỹ thuật tự động hóa gợi ý (phần giữa)
- Nói chuyện sơ lược về DSPy và kỹ thuật tự động hóa gợi ý (phần đầu)
- Kiến thức phổ thông: Giải mã nguyên lý xác suất đằng sau LLM
- Bắt đầu từ Vương Tiểu Bảo: ranh giới đạo đức và quan điểm thiện ác của người bình thường
- Xem xét lại thông tin qua GraphRAG
- Những thay đổi và bất biến trong sự thay đổi công nghệ: Làm thế nào để tạo ra token nhanh hơn?
- Thể trí doanh nghiệp, số hóa và phân công ngành nghề trong lĩnh vực